AMD Fiji 雖然還未發表,不過從 SK hynix HBM 架構還是能夠分析出將會是款什麼樣的晶片。
目前對於 6 月份 Computex 後才會發表的 AMD Radeon 旗艦 Fiji 晶片各方說法都不一,不過我們仍然可以透過 SK hynix 的次世代 HBM 架構進行 AMD Fiji 晶片的一些分析。
目前從 Videocardz 所曝光的一些 AMD Radeon R9 390X WCE 的簡報中可以發現,將會具備 4096 個 SP、256 個 TMU、64 個 ROP,需要 PCIe 6pin + 8pin 或者是 2 組 PCIe 8pin 的供電,不過最讓人好奇的是在 HBM 規模從原先的 4GB 擴展到 8GB。

簡報中指出了從 4GB 提升為 8GB 的方式,主要為加入 Dual-link interposing 機制,而這個機制才是我們所關心的重點。

先來談談 HBM 吧,可能各位對於 HBM 只有很初步的認識就是 Stacked memory or Stacked dram(堆疊記憶體),而造就能夠堆疊的原因主要是因為 TSV(through silicon via),透過在矽晶圓上開孔搭配 micro bump 將 2 個矽晶圓連接在一起。

對於 HBM 有初步的認識後,再來聊聊內部組成。
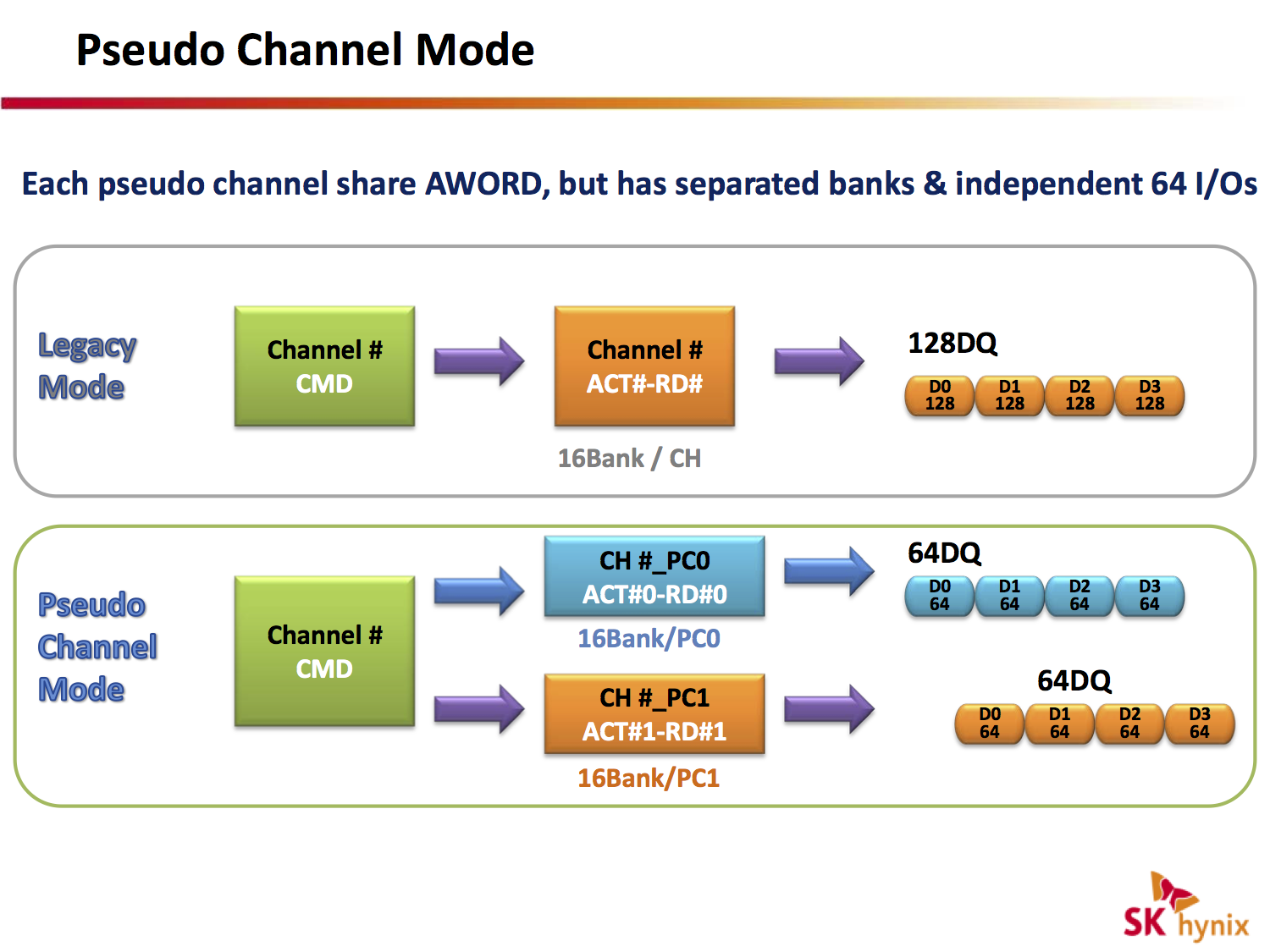
HBM 預計推出 4Hi、8Hi 版本,而目前所使用到的都是 4Hi 版本,也就是堆疊 4 層(4 dram die + 1 base logic die),而內部每層當中,又會有 2 個 Channel,造就目前 HBM 中擁有 8 個 Channel,而每個 Channel 當中又可以劃分為 8 or 16 個 Bank,這個 Bank 就是組成 HBM 最小的一個單位,當然在 Bank 之下還有 Row & Column 排列的電容。

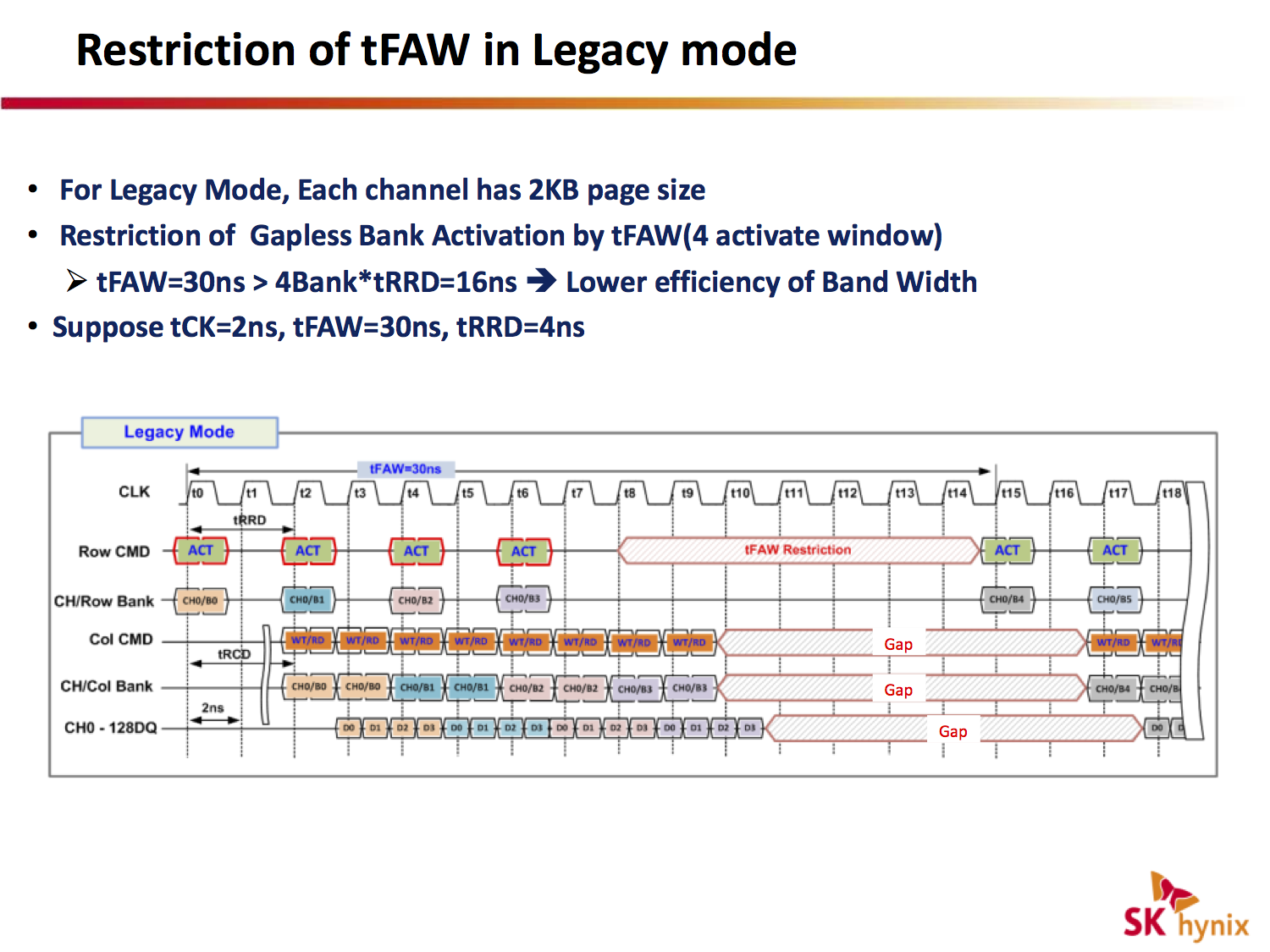
在 HBM2 則是會新增 Pseudo Channel,能夠將 page size 從原先的 2KB 拆為 1KB,解決長久以來 tFAW 週期內限制 4 Activations 的問題,從原先的 tFAW 2KB x 4 ACT,變更為 tEAW 1KB x 8 ACT,增加頻寬利用率。



那麼對於 AMD 將採用的 HBM,他到底長什麼樣子呢?以下就來分析實作可行性。
容量怎麼變成 8GB 呢?我們目前已經知道 HBM 第 1 代原先預計採用 2Gb 顆粒進行堆疊,總共 4 層組成 8Gb(1GB)。不過從最新 SK hynix 資料中來看,新的 HBM 將會採用 4Gb 顆粒進行堆疊(每 1 Cahnnel 為 2Gb),4Hi 即為 2GB,4 顆 HBM 即為 8GB。

為什麼會變成單層 4Gb 呢?
從 JEDEC 所提供的文件中可以發現 HBM Channel Address 採用的方式為 1、2Gb 顆粒都是 8 Bank 設計,其中容量增加的關鍵在 Row Address 從原先的 13bit 增加為 14bit。*計算方式:2^3(Bank)x 2^6(Column)x 2^14(Row)x 256bit = 2Gb。

單層 8Gb 則是從這個基礎上再增加 1 倍 Bank 達成,所以網路上猜測容量倍增是否是增加了 Bank 數量從原先的 8 增加為 16,這個假設是不成立的情形。另外在簡報中,特別指出了容量增加是採用 Dual-Link interposing 的方式達成,且 HBM2 預計將不需要這種方式,那麼 Row Address 增加的方式在這段敘述中就不成立,顯然 AMD 採這個方式的機率較低。
另外網路上也猜測是否為 HBM 加上 GDDR5 的組合,雖然 HBM 是有類似應用,不過這種組合顯然與需要大頻寬的 GPU 架構不太相符。且該應用變相需在單顆 GPU 中同時擁有 HBM 控制器與 GDDR5 控制器,與下一階級 Radeon R9 390 只有 4GB 的規格相去甚遠,這個方案可行性非常低。

那麼還有方式來增加容量嗎?有的,不過這種方式其實有一點蠢,在原先由 4 顆 4Hi HBM 1GB 的基礎下增加為 8 顆,即可達到所謂的 8GB。不過為什麼可以這麼做呢?這部份恐怕得回到記憶體架構 Rank 數量的概念,簡單略述即為共用訊號線,透過 Chip select 的方式切換不同 Rank 的 HBM。

這種方式既符合 Dual-Link interposing 的敘述,同時也可以簡化等級區分難度,同時在 HBM2 因為單一 HBM 容量激增的緣故,也不再需要透過增加 HBM 顆粒的方式來增加容量。
不過一開始就說過這種方式有點蠢,原因其實不外乎在於成本增加之外,還增加了整塊 Substrate 與 Interposing 的面積。同時散熱也面臨到需要更大的問題,且由於是 2 個獨立的 HBM 需要透過 chip select 去切換,無疑徒增延遲的問題。
不過實際到底如何運作,還是得實際看到樣品才能確認,各位覺得 AMD 會選擇什麼方式呢?