DLSS 3 真的很強,同時 Ada Lovelace 架構也有很多特色。
NVIDIA GeForce RTX 40 系列在 9 月 20 日正式發表,而 NVIDIA 則是與全球媒體在 9 月 21 日闡明更多 Ada Lovelace GPU 架構的細節與 GeForce RTX 40 系列的特色。
新一代 GeForce RTX 40 系列採用 Ada Lovelace 架構,現階段發表了 GeForce RTX 4090 24GB GDDR6x,確定會在 10 月 12 日發售,緊接其後會是 GeForce RTX 4080 16GB GDDR6x 與 GeForce RTX 4080 12GB GDDR6x,發售時間目前暫定在 11 月份。

目前 Ada Lovelace 架構中,旗艦的 GeForce RTX 4090 採用 AD102 晶片,16GB 與 12GB 的 GeForce RTX 4080 系列分別使用 AD103 與 AD104 晶片。
NVIDIA 明確提到 Ada Lovelace 架構擁有新的 Streaming Processors、RT Core、Tensor Core、Optical Flow Accelerator 與 Video Engine。
Video Engine 部分,GeForce RTX 40 系列與 GeForce RTX 30 系列相比較的話,新一代顯示卡擁有 2x NVENC(第 8 代)與 1x NVDEC(第 5 代);GeForce RTX 30 系列為 1x NVENC(第 7 代)與 1x NVDEC(第 5 代)。主要不同在與 NVENC,這也讓 GeForce RTX 40 系列可以在 8K 60Hz 部分更為強悍。
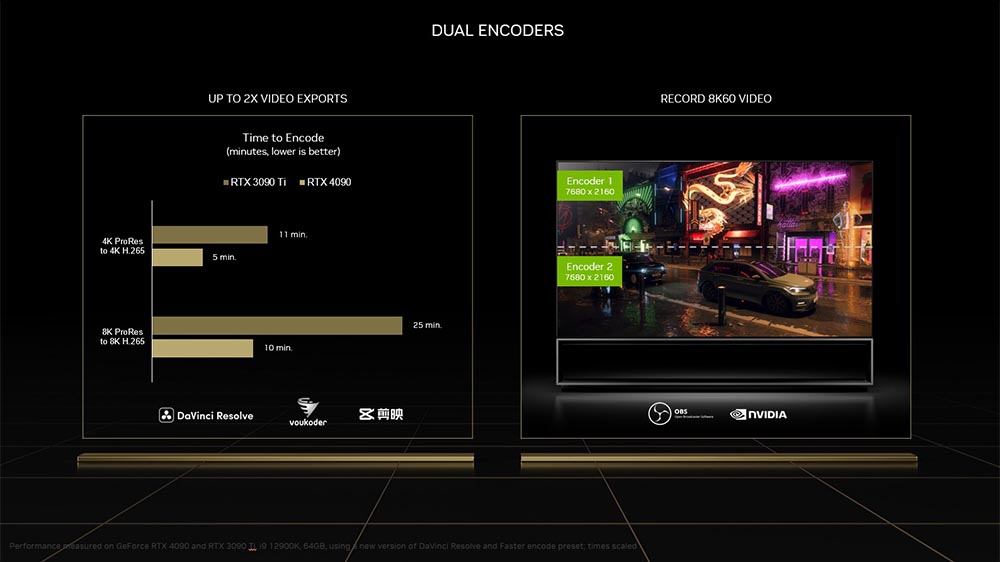
GeForce RTX 40 系列也擁有 H.264、H.265 與 AV1 格式的編解碼能力。
回到 Ada Lovelace 架構上,跟著來看看它與 2020 年發表的 Ampere 架構差異到底有多大。
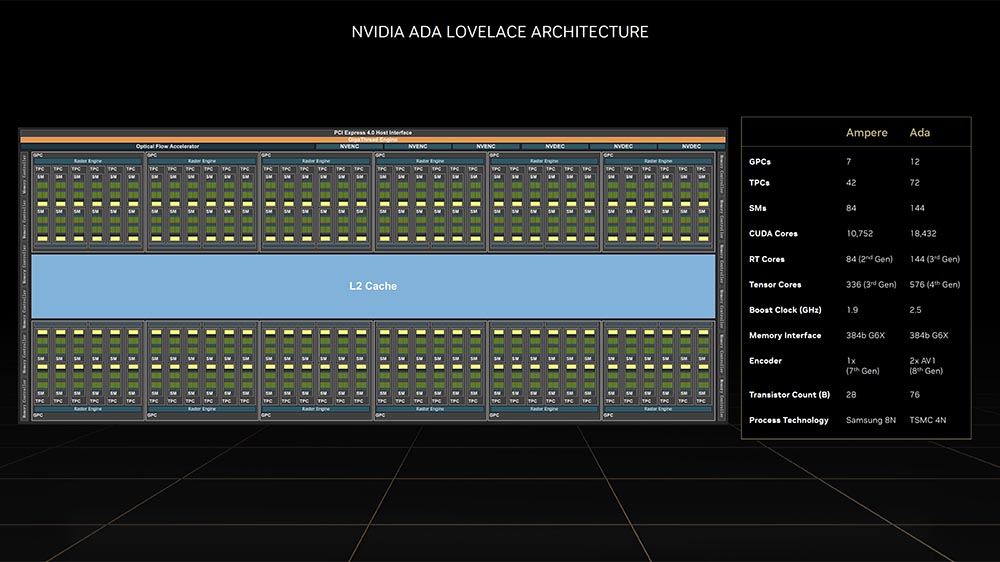
Ada Lovelace 推進到 TSMC 4nm 製程,與 Ampere 架構的 Samsung 8nm 製程有著非常大的不同。
首先在 GPCs(Graphics Processing Clusters),AD102 從原先 GA102 的 7 組提升至 12 組,至於每 1 組 GPCs 是由 6 組 TPCs(Texture Processing Clusters)組成,再來就是每個 TPCs 整合 2 個 SMs(Streaming Multiprocessors),每組 SMs 整合第 3 代 RT Core、128KB L1 快取與 4 個 TMUs(Texture Mapping Units),同時 4 個集群(clusters)各擁有 16 FP32 CUDA Cores、16 個同步 FP32 + INT32 CUDA Cores、4 load / store units 與帶有 warp-scheduler 和 threat-dispatch 功能的 L0 快取;當然,這裡面更重要的是第 4 代 Tensor Cores。
總結來說,Ada Lovelace 每組 SM 擁有 128 CUDA Cores、4 個 Tensor Cores 與 1 個 RT Core;每 GPC 擁有 12 SMs,也就是 1,536 CUDA Cores、48 個 Tensor Cores 和 12 個 RT Cores。因此,12 個 GPCs 可以提供多大 18,432 CUDA Cores、576 個 Tensor Cores 與 144 RT Cores;此外,每組 GPU 擁有 16 RPOs,也就是說 AD102 擁有多達 192 ROPs。
Ada Lovelace 仍舊維持 PCIe 4.0 x16 與 384 bit 記憶體介面。
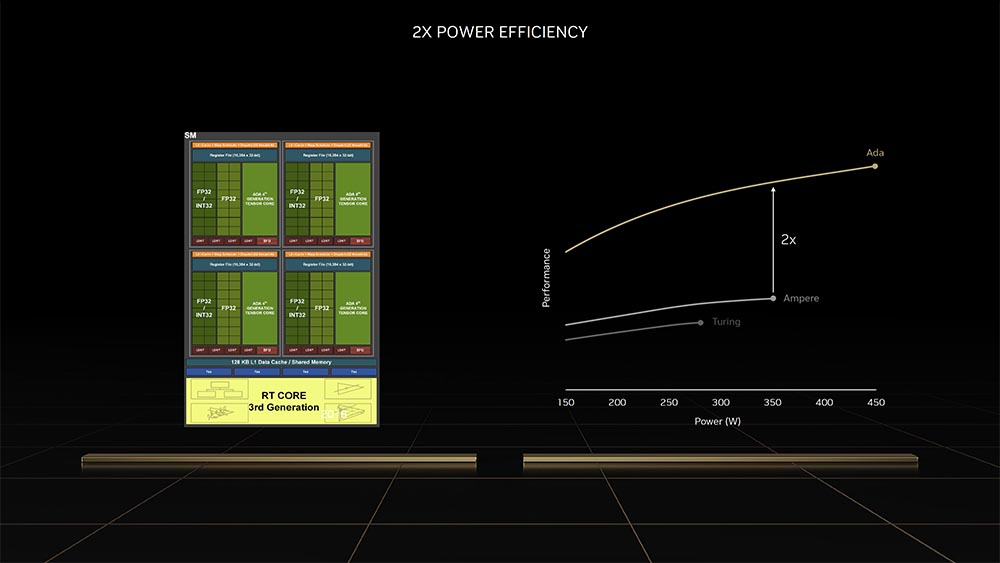
效能提升當然也會迫使功耗往上增加,可是與 Ampere 相比較的話,在同樣功耗的前提下,可以見到 Ada Lovelace 表現是有相當 2x 幅度的增加;AD102 aka GeForce RTX 4090 預設 TGP 為 450W。

Ada Lovelace 架構 GPU 的新功能包含 SER(Shader Execution Reordering)、DMM(Displace micro-mesh)、OMM(Opacity micro-masks)、FP8 Inferencing、Optical Flow Accelerator 與 DLSS 3。
在眾多新功能裡面,DLSS 3 的加入可以說是個革命性的特色。
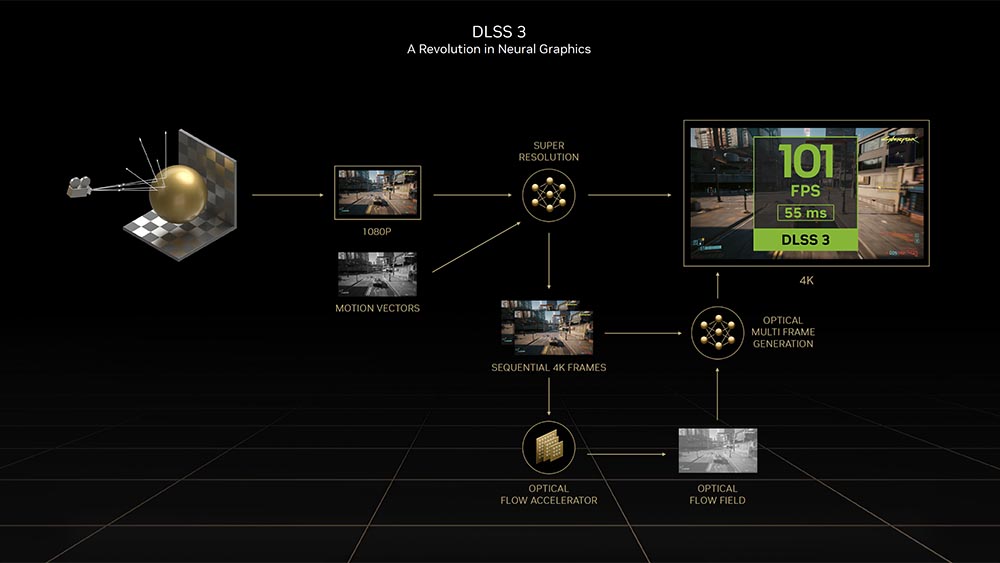
DLSS 3 具有 DLSS 2 的所有功能與 AI super-resolution,但它新加入的 AI frame-generation 特色讓同等質量的條件下,可以將幀速率提高近一倍。另一方面,DLSS 3 可以不投過圖形渲染管道的前提下,簡單透過 AI 生成整個畫面。
DLSS 3 引入了一項革命性的新功能,該功能有望在同等質量的情況下將幀速率提高近一倍,稱為 AI 幀生成。雖然它具有 DLSS 2 的所有功能及其 AI 超分辨率(以最小的質量損失將較低分辨率的幀放大到原始分辨率); DLSS 3 可以簡單地使用 AI 生成整個幀,而不涉及圖形渲染管道。因此,使用 DLSS 3 的每個交替幀都是 AI 生成的,而不是先前渲染幀的副本。
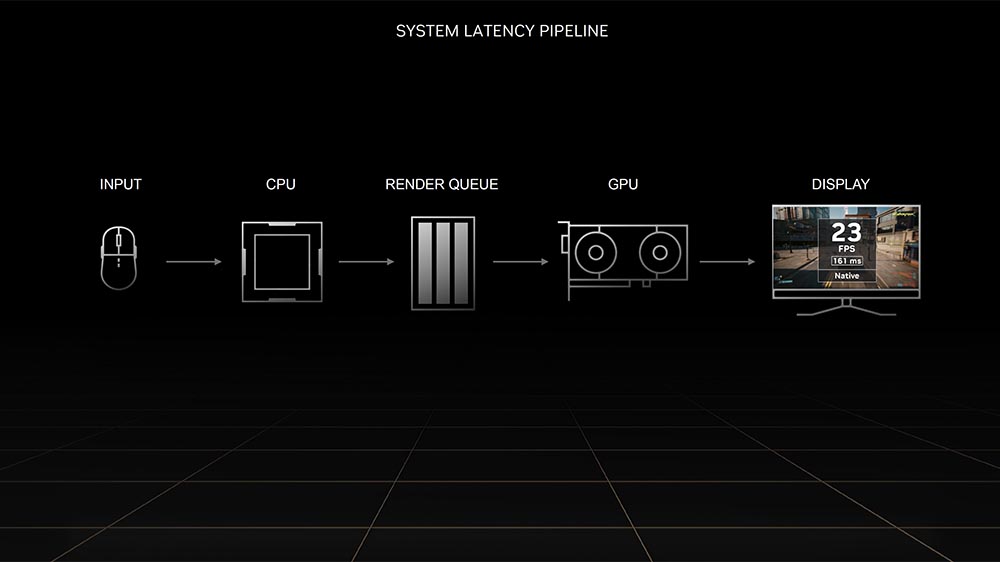

只能在 Ada Lovelace 架構 GPU 實現的原因,主要在於 Optical Flow Accelerator(OFA)硬體,透過它創建所謂的光流場預測下一個畫面的外觀。OFA 同時也確保 DLSS 3 演算法不會被快速變化的 3D 場景中的靜態對象所混淆,這很大程度是仰賴第 4 代 Tensor Cores 的 FP8 所帶來的效能提升。

DLSS 3 最後一個要素就是 Reflex。透過降低 rendering queue to zero,Reflex 在 DLSS 3 幀時間中扮演則著至關重要的作用,並且確保渲染隊列不會混淆 upscaler。OFA 與第 4 代 Tensor Cores 的結合,是 Ada Lovelace 擁有 DLSS 3 的原因,這也是 Ampere 以及其他舊架構無法運行的主因。