Intel i740 沒跟到!Larrabee 拉拉比被砍掉!這次一定要用賢者之石練成顯示卡!(疑?)
2021 年科技業界最震撼的消息,Intel 再度重返獨立顯示卡絕對可以記上一筆!並一口氣宣布推出 Alchemist、Battlemage、Celestial、Druid 4 代產品。以事後諸葛的角度來看,推出過程縱使不順遂,歷經驅動程式不成熟、一再延遲,甚至傳出砍掉 AXG 事業部門還無法重練的消息,幸好終於在 2022 年 10 月推出第一世代最高階 Arc A770 和 Arc 750 獨立顯示卡作品。
超越當代顯示卡的功能
以第一世代 Alchemist 規格來看,Intel 的野心其實十分明顯,包含硬體支援 DirectX 12 Ultimate 規格、硬體重新排序光線追蹤工作、XMX 矩陣運算引擎、AV1 硬體編碼、Smooth Sync,軟體則推出 XeSS 人工智慧超取樣技術,功能上甚至還超越 AMD、NVIDIA 現有產品。話不多說,趕快來看看 Intel 這塊大餅是用什麼好料畫出來!?
▼「千呼萬喚始出來」,繼 2022 年 6 月於中國正式開賣採用 ACM-G11 晶片設計的 Intel Arc A380 之後,2022 年 10 月於全球推出採用 ACM-G10 晶片設計的 Intel Arc A770/A750,Intel Arc A580 也會採用這個晶片版本。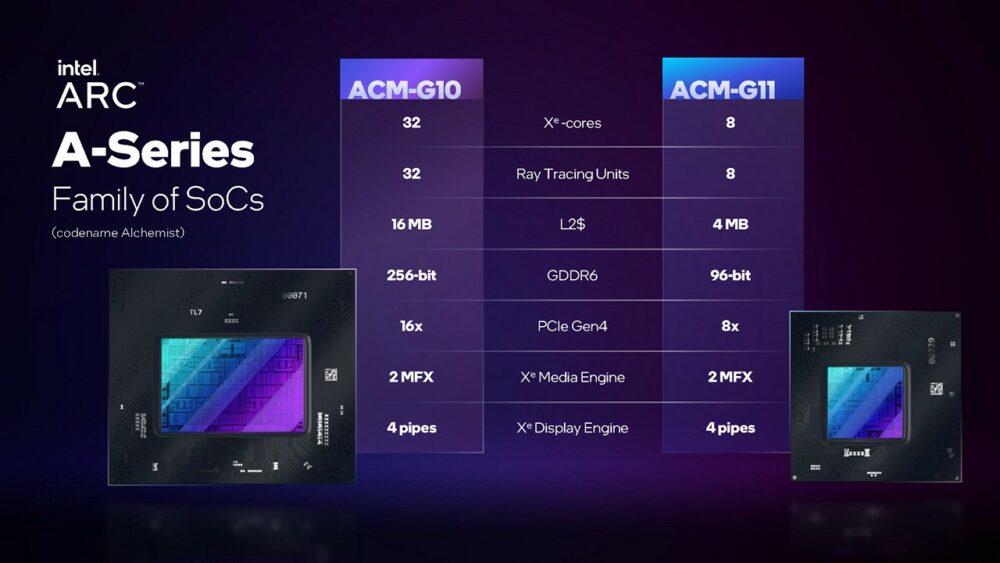
第一世代採用 Alchemist 架構晶片預計將有 2 款,ACM-G11 是比較小型的設計,僅有 8 個 Xe 核心(1 個 Xe 核心約有內建顯示繪圖核心所稱的 16 個 EU、但須注意 Xe 核心還多了一些東西)、GDDR6 記憶體通道寬度為 96bit;ACM-G10 則是最大的設計,可達 32 個 Xe 核心,GDDR6 記憶體通道寬度則達 256bit。
所有採用 Alchemist 架構的晶片均透過 TSMC N6 製程製造,ACM-G11 晶片尺寸約為 157mm2,內含 72 億個電晶體;ACM-G10 晶片尺寸約為 406mm2,內含 217 億個電晶體。Intel 官方賦予這 2 款晶片製成的桌上型 Arc A380 和 Arc A770 獨立顯示卡,運作時脈在 2GHz 以上,TBP(Total Board Power)分別為 75W 和 225W。當然,合作廠商可以根據需求自行調整。
▼ 市場預計將會見到 5 款採用 Alchemist 架構的 Arc A 系列桌上型獨立顯示卡,Arc A770 則會推出 8GB 和 16GB 記憶體版本。這系列顯示卡均具備同樣的特效功能,僅以效能高低作為區分。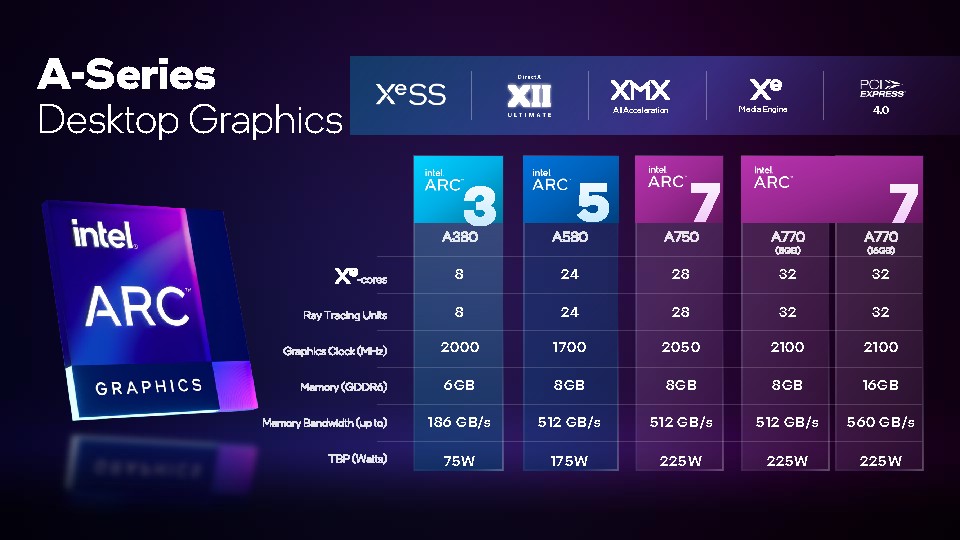
Xe-LP、Xe-HPG、Xe-HPC
Intel 原先預計推出 4 款針對不同市場的架構設計,內建圖形顯示 Xe-LP、遊戲市場 Xe-HPG、資料中心 Xe-HP、高效能運算 Xe-HPC,但是 Xe-HP 已不會推出,僅做為自家開發工具使用,這一塊資料中心市場目前由 Xe-HPG 補上,推出 Intel Data Center GPU Flex 系列。
另外一個比較有趣的部份,除了用於超級運算的 Xe-HPC 以外,其餘全部不具備硬體 FP64 運算能力,需透過軟體模擬,與 AMD、NVIDIA 切割市場而屏蔽硬體處理 FP64 速度的方式並不相同。不過娛樂用顯示卡幾乎不需要 FP64 運算能力,砍掉也無妨。
▼ Xe-HPG 相較於 Xe-LP,提供獨立的浮點運算路徑。單一向量引擎寬度為 256bit,支援 8 個 FP32 SIMD 運算。
▼ Xe-HPG 每個 Xe 向量引擎的後方還銜接 1 個寬度為 1024bit 的 XMX 矩陣引擎,提供更高的 FP16/INT8 運算能力,並額外支援 BF16/INT4/INT2 格式。
▼ 單一 Xe 核心之中,透過著色器每個時脈可執行 16 次 INT8 運算,使用 DP4a 指令集則是提升至每個時脈 64 次運算,XMX 矩陣引擎則是大幅提升至每時脈週期 256 次運算,加快人工智慧推論結果產出。
▼ 單一 Xe 核心具有 16 個向量引擎、16 個矩陣引擎、192KB L1 快取 ∕ Shared Local Memory。
Xe-HPG 的組成單元最小為 Xe 核心,每個 Xe 核心內部有 16 個向量引擎和 16 個矩陣引擎,並擁有自己的儲存∕載入單元、指令快取、L1 快取 ∕ Shared Local Memory。每個 Xe 核心也對應 1 個執行緒排序單元和 1 個光線追蹤單元,再加上取樣單元、幾何單元、光柵單元、HiZ 剔除單元、像素後端單元……等,4 個 Xe 核心組合成 1 個 Render Slice。
▼ Xe-HPG 每個 Render Slice 包含 4 個 Xe 核心和 4 個光線追蹤單元。
Xe-HPG 的光線追蹤單元除了目前大家熟知的 Ray Traversal、Bounding Box Intersection、Triangle Intersection 功能之外,Intel 於今年 4 月底舉行的 GDC 2022 向外宣布,Xe-HPG 光線追蹤工作還能夠以硬體的方式,將工作內容相近的光線追蹤執行緒排在一起運算,這有助於資源重複利用並加快運算速度。競爭對手 NVIDIA 直到 GeForce RTX 40 系列才加入,AMD 則還在苦苦追趕光線追蹤各項功能當中。
延伸閱讀:A Quick Guide to Intel’s Ray-Tracing Hardware | GDC 2022 | Intel Software
另一方面,為了加速 Bounding Box Intersection、Triangle Intersection 等作業,光線追蹤單元內建 1 個 BVH(Bounding Volume Hierarchy)快取,每個光線追蹤單元內含 2 條 Traversal Pipeline,峰值效能加總每個時脈可達 12 次 Box Intersection 和 1 次 Triangle Intersection。
▼ 不同的光線追蹤工作,從攝影機反向射出的光線有可能很快就返回碰撞結果,也有可能碰撞到物體後再反射進入另外的執行迴圈,也有可能完全沒有碰撞到場景中的物件,因此每個光線追蹤工作時間、所需資源不盡相同,容易造成硬體資源的浪費。
▼ Xe-HPG 執行緒排序單元能夠將相近的光線追蹤工作排在一起處理,達到資源重複利用、加速運算的效果。
▼ Xe-HPG 單一光線追蹤單元,每個時脈最高可達 12 次 Box Intersection 和 1 次 Triangle Intersection。
▼ 相較於不具備著色器執行緒排序功能的 GeForce RTX 3060,Arc A770 光線追蹤效能優勢十分明顯。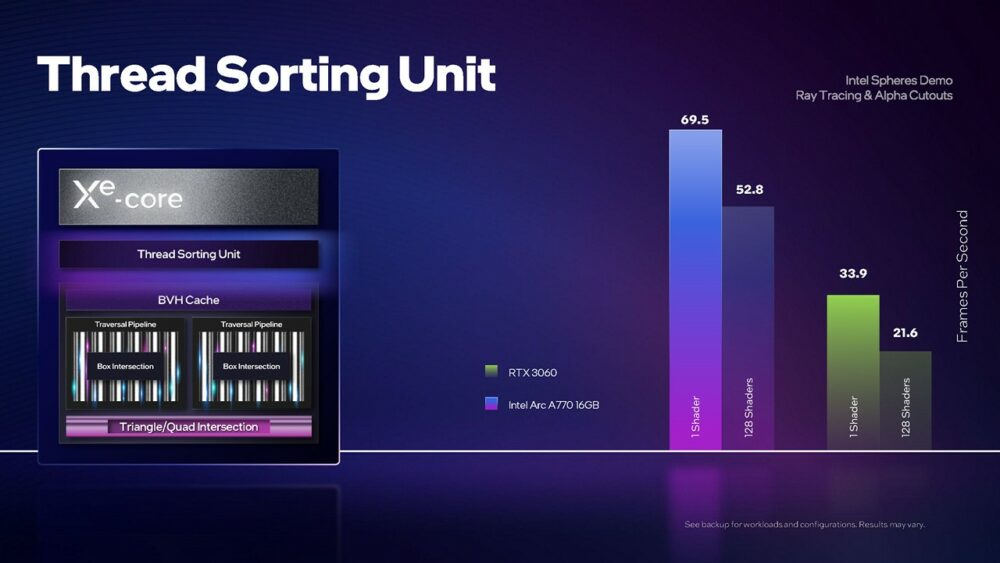
媒體引擎支援 AV1 硬體編碼
Alchemist 架構顯示卡另外一項創舉,是在媒體單元中新增 AV1 硬體編碼能力(第 12 代、第 13 代 Intel Core 處理器僅內建 AV1 硬體解碼能力),最高可達 8K60 12bit HDR 硬體解碼、8K 10bit HDR 硬體編碼,原先 H.264(AVC)/H.265(HEVC) 硬體編解碼、VP9 硬體解碼也繼承下來。從 Sandy Bridge 世代 Intel HD Graphics 就具備的 VC-1 硬體解碼功能則被拔除,畢竟現在使用 Windows Media Video 技術的影片,已經比日本製壓縮機還要稀少。
▼ Alchemist 架構的媒體引擎支援 AV1 12bit 硬體解碼和 AV1 10bit 硬體編碼。
4 條畫面輸出通道、簡單卻有效的 Smooth Sync
Alchemist 架構具備 4 條畫面顯示輸出通道,其中 1 條還針對低功耗運作最佳化,並支援 DisplayPort 1.4/2.0 10Gbps、HDMI 2.0b,最高同步輸出 4 個 4K120 HDR 畫面或是 2 個 8K60 HDR 畫面。如果需要支援 HDMI 2.1,就須另行在顯示卡上安裝 1 個協定轉換晶片。
▼ Alchemist 架構具備 4 條畫面顯示輸出通道,原生支援 DisplayPort 1.4/2.0 10Gbps、HDMI 2.0b。
自從 NVIDIA 推出 G-SYNC 之後,「畫面顯示垂直同步」議題就不斷地受到大家關注,競爭對手 AMD 推出 FreeSync,視訊產業標準制定協會 VESA 則是推出 AdaptiveSync,其它還有以取巧方式兼顧畫面品質與輸出延遲的各項技術。Intel 在此則是擁抱 VESA 標準 AdaptiveSync,並把自家輸出畫面緩衝區最後 1 張完整畫面的技術,稱之為 Speed Sync(運作原理和 NVIDIA Fast Sync 相同)。
Alchemist 架構還支援另一種 Smooth Sync,基本上與完全不做任何垂直同步的畫面輸出方式相同,當顯示卡畫面輸出速率與螢幕顯示速率不同時,就會觀察到撕裂現象。不過 Smooth Sync 會在前一張畫面和後一張畫面交界處加入 dithering filter,讓畫面撕裂看起來不那麼地明顯,且適用於一般螢幕。
▼ Alchemist 架構支援 3 種顯示畫面撕裂的改善方式,分別為 AdaptiveSync、Speed Sync、Smooth Sync。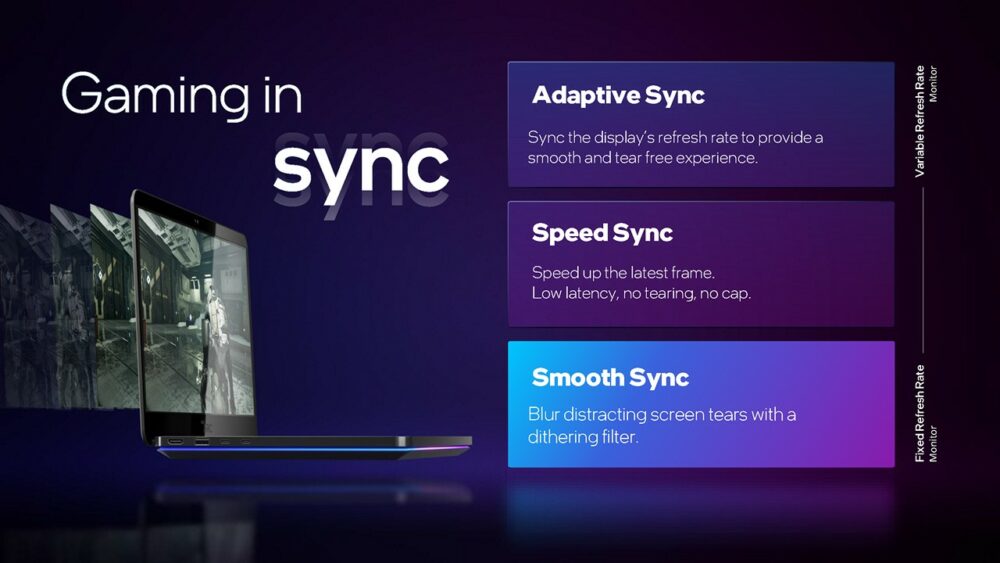
▼ Smooth Sync 顯示畫面仍舊有撕裂現象,但在前一張畫面和後一張畫面交界處加入 dithering filter 糢糊不連續邊界,讓人眼不易察覺畫面撕裂,是個十分聰明的作法,並相容所有遊戲和一般螢幕。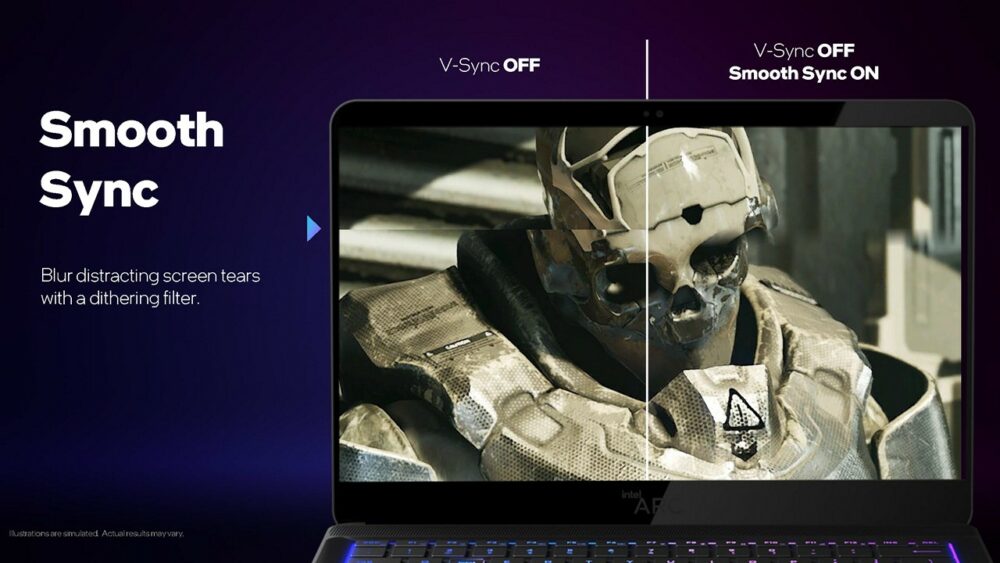
▼ Intel Arc Control 公用程式也會加入顯示卡遙測、OSD 資訊顯示、超頻等功能,而且「不需要登入帳號」。部分遊戲則支援 Automatic Game Highlights 功能,自動錄製一小段值得紀念的影片。
XeSS 人工智慧超取樣技術
NVIDIA 有 DLSS,Intel 也有與之對應的 XeSS 技術,但相較於 DLSS 只能在具備 Tensor 核心的顯示卡使用,XeSS 則能夠在沒有 XMX 矩陣引擎的情況下,透過 DP4a 指令以類似的實作方式呈現(顯示卡需支援 HLSL Shader Model 6.4),特別是還沒有類似人工智慧解決方案的 AMD 顯示卡。XeSS 需要遊戲開發商將此功能整合在遊戲之中,無法如同 AMD RSR(Radeon Super Resolution)直接從驅動程式開啟即可。
XeSS 同樣透過深度學習演算法,訓練模型能夠從低解析度畫面生成高解析度畫面,XeSS 要求遊戲提供提供低解析度畫面、高解析度動態向量,若無法提供高解析度動態向量資訊,也可以提供低解析度動態向量和深度資訊;攝影機朝向遊戲場景拍攝時則需要加入 jitter(建議使用 Halton(2, 3) 序列)略為移動拍攝位置(以便取得更多畫面資訊並強化反鋸齒效果),也會建議開發商將 Mipmap 偏移適度地調低(使用較高解析度的材質)。最後輸出的高解析度圖片,也會回饋至 XeSS 當中,以便處理物件材質被遮蔽,忽隱忽現容易讓畫面破碎的問題。
▼ 藉由 XeSS 技術,就能夠以較低的解析度進行畫面渲染工作,提升遊戲畫面幀數,最終亦能夠輸出高解析度、高品質的畫面。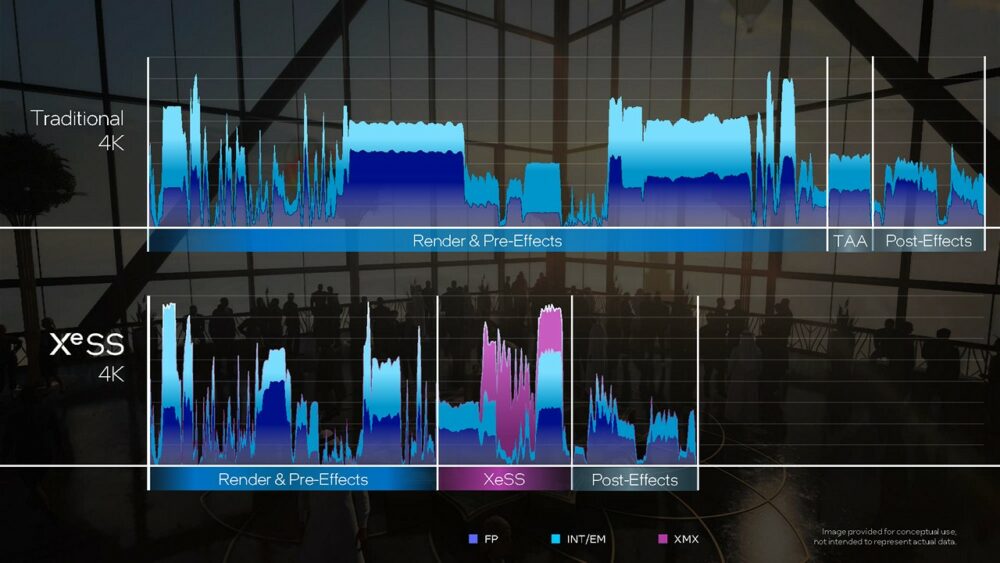
▼ 以畫面渲染流程來看,XeSS 主要是取代了過往 TAA 階段。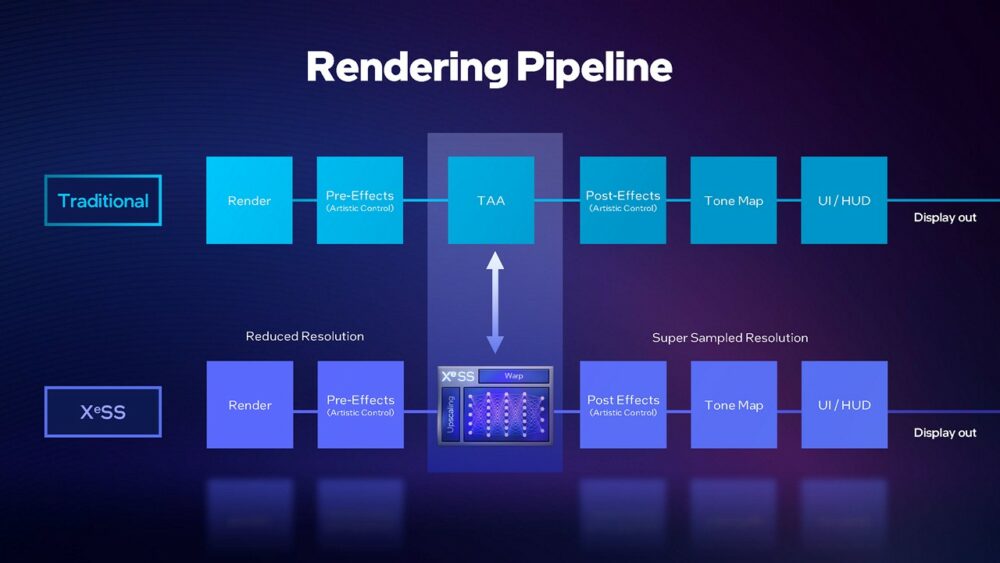
▼ XeSS 需要整合至遊戲當中,提供較低解析度畫面和動態向量資訊,生成的較高解析度畫面也會持續地回饋至 XeSS 當中。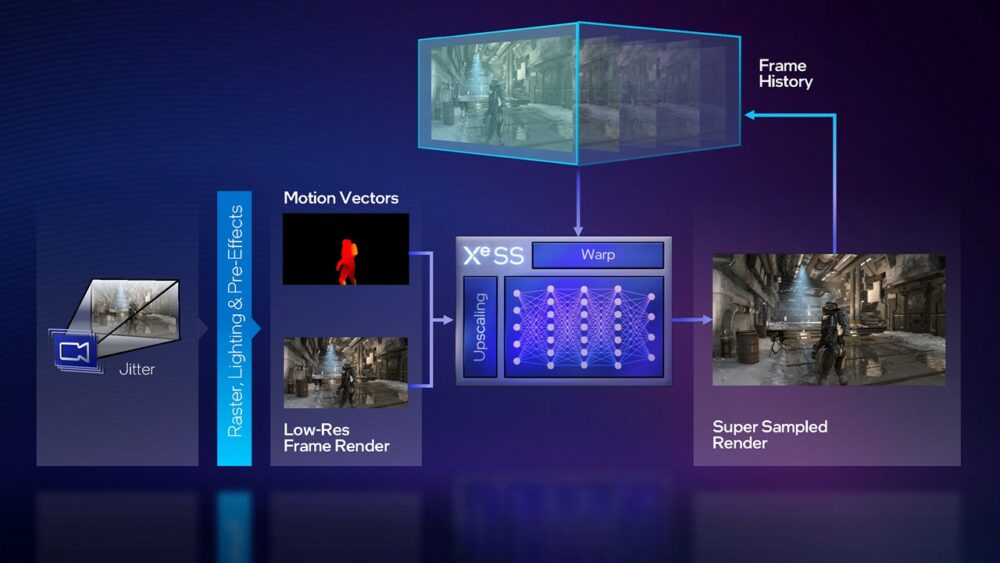
▼ XMX 和 DP4a 執行 INT8 資料型態的運算量比較。
▼ XeSS 不限 XMX 矩陣引擎的顯示卡才能夠執行,可執行 DP4a 指令的 Intel 內建圖形顯示或是其它支援 HLSL Shader Model 6.4 顯示卡也能夠使用,只是運算能力有限無法使用較複雜的模型。
▼ XeSS 將提供 4 種畫質選項:Ultra Quality、Quality、Balanced、Performance,其內部渲染解析度大約是畫面解析度的 0.766 倍、0.666 倍、0.583 倍、0.5 倍。
▼ ACM-G10 SoC 整體功能架構圖。
▼ Intel Arc A770 / A750 Limited Edition 規格一覽。Intel Arc A770 8GB 建議零售價將從 329 美元起跳、16GB 則從 349 美元起跳,Intel Arc A750 建議零售價將從 289 美元起跳。
比較可惜的是由於某些緣故,Intel Arc A 系列獨立顯示卡錯失最好的上市時間,整體軟、硬體架構開發方向也偏向最新 API(DirectX 12、Vulkan),DirectX 9/10/11、OpenGL 等需要驅動程式最佳化的 API,目前 Intel 仍持續努力當中,就連記憶體控制器的設計方式,也以支援 Resizable BAR 為主。Intel Arc A 系列獨立顯示卡若是安裝在有些年紀,不支援 Resizable BAR 的電腦系統上,會見到幅度可觀的效能減損現象。
延伸閱讀:DF Direct Special: Inside Intel Arc – What’s Happening With GPUs, XeSS and Ray Tracing?
幸好 Intel 在定價策略上相當大方,將以 Tier 3(使用舊 API 且未最佳化)遊戲內部測試的效能結果進行定價,因此消費者可以使用比較便宜的價格,獲取較高的 Tier 1(使用現代 API 且已最佳化)、Tier 2(使用現代 API 但未全面最佳化)遊戲效能,算是這位剛踏入獨立顯示卡市場的玩家,給大眾的福利。