NVIDIA 於 Editor’s Day 不僅介紹該系列顯示卡的規格變化,也提供省電機制的說明。
因應導入 Neural Rendering
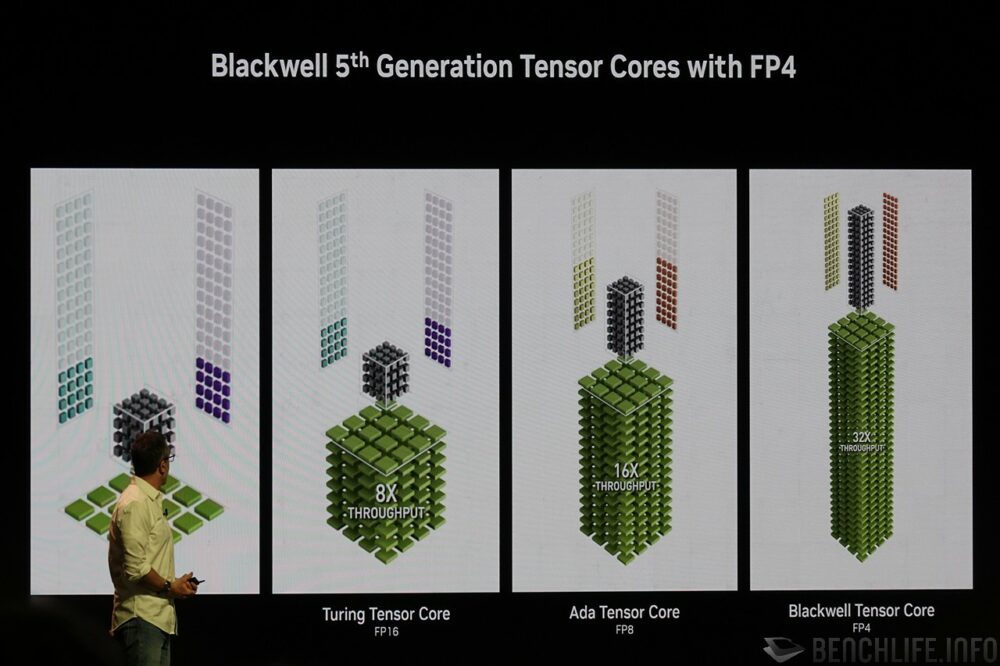
NVIDIA 於 Editor’s Day 即說道,目前我們對於畫面品質的追求,已大幅度超越摩爾定律能夠提供的運算能力,導入 Neural Rendering 勢在必行。用於 GeForce RTX 50 系列顯示卡的 Blackwell 架構,由於其張量核心 Tensor Core 新增支援 FP4 浮點運算,整張顯示卡全部加總後的運算能力甚至高達 4000 AI TOPS(以最高階 GeForce RTX 5090 計)。
▼ NVIDIA 認為,在這後摩爾定律時代,導入 Neural Rendering 是個不錯的解方。
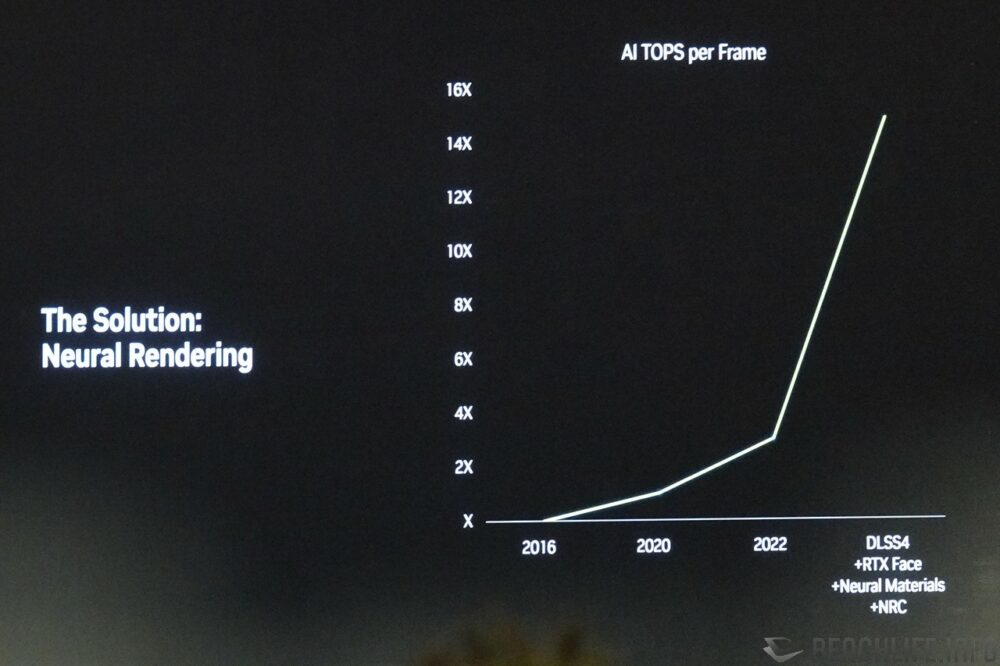
▼ Blackwell 新增、改善許多特點,除了改採 GDDR7 視訊記憶體之外,其 Tensor Core 也支援 FP4 浮點運算,全部加總提供最高達 4000 AI TOPS。

▼ Blackwell 的張量核心支援 FP4 符點運算,相較第一世代 Pascal 張量核心可達成 32 倍的吞吐運算量。
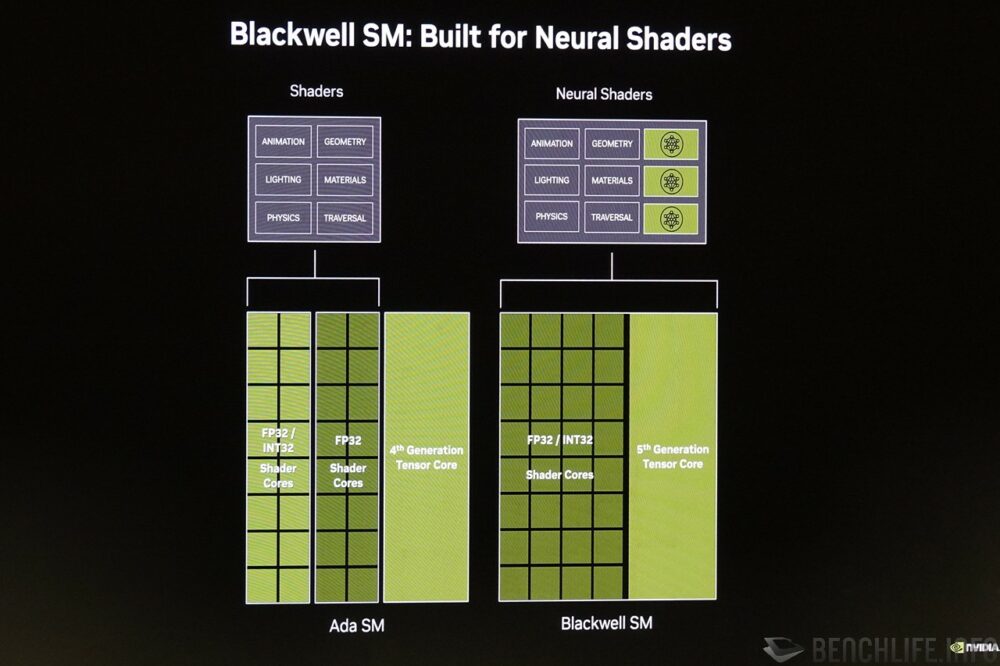
由於導入 Neural Rendering,Blackwell 架構的串流多處理器 Streaming Multiprocessor 連帶也出現一些變化,與張量核心 Tensor Core 更為緊密的結合,以便在傳統渲染繪圖管線的中段導入 AI 相關功能,且著色器核心 Shader Core 也不再區分可以處理 INT32 / FP32 以及僅能處理 FP32 的部分,Blackwell 的 Shader Core 一律均可操作 INT32 / FP32 資料。
▼ Blackwell 進一步結合傳統著色器核心和張量核心,打造出 Neural Shader,且內部著色器核心均可支援 INT32 / FP32 運算。
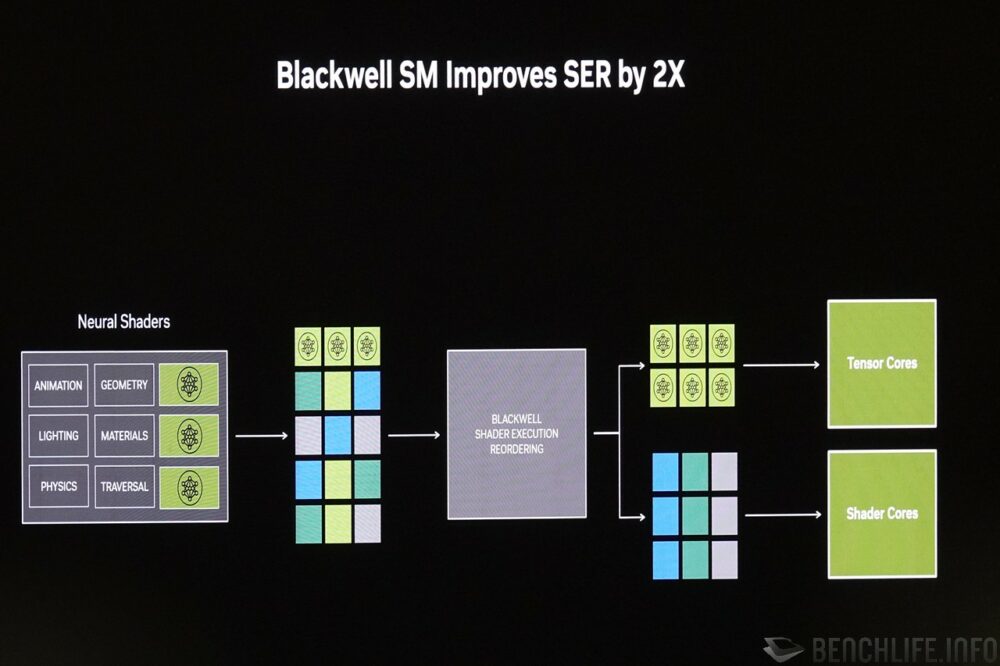
▼ 由於 Neural Shader 會有多種運算作業混用的情形,NVIDIA 也為此打造出 Shader Execution Reordering 功能,將不同的工作分配到著色器核心或是張量核心。
更有效率的 RT 核心
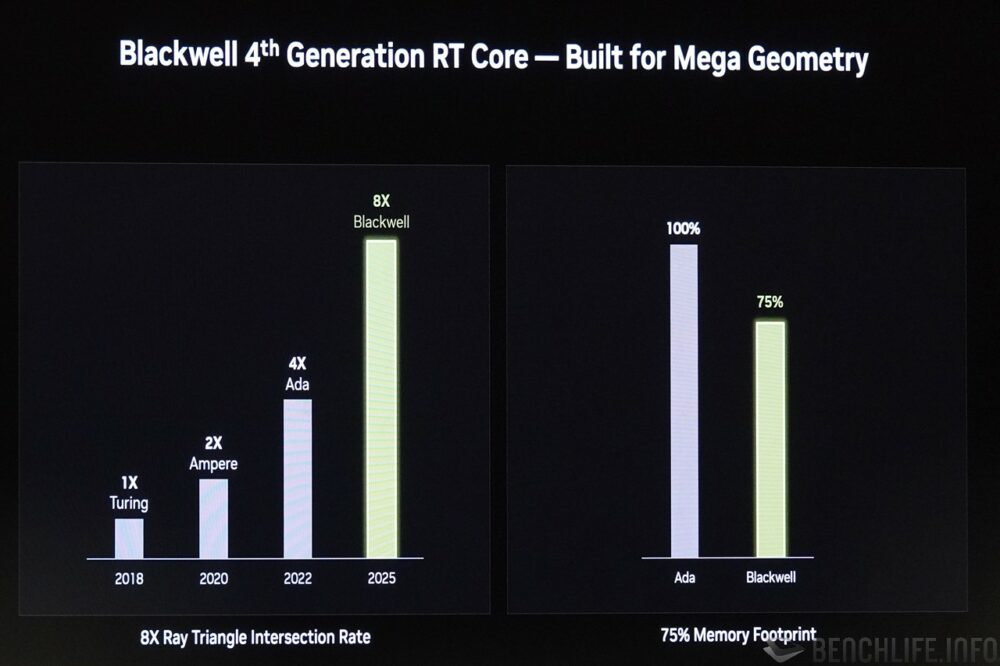
RT 核心部分,新增支援 Linear-swept Spheres,光線、路徑與三角形相交的檢測如今能夠以叢集(cluster)的方式進行,提升檢測時的效能。另外也有三角形叢集解壓縮引擎,其目的同樣是以較具效率的方式執行 BVH 遍歷並節省記憶體使用率。
▼ RT 核心也有不少的新增功能,主要提升檢測光線、路徑與三角形相交的效能。

▼ Blackwell 相較於首次加入 RT 核心的 Turing 世代,其光線、路徑與三角形相交的檢測效能大約提升至 8 倍,相較前一世代 Ada Lovelace 亦可節省約 25% 記憶體使用率。
首次使用 GDDR7
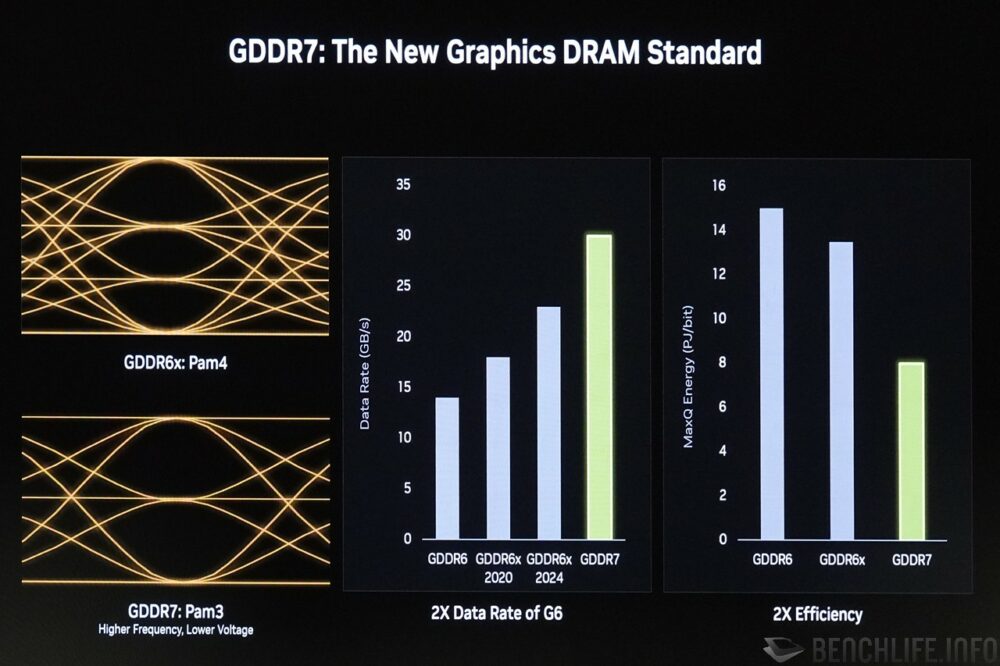
Blackwell 在整體晶片外的優勢,就是創新搶先採用 GDDR7 視訊記憶體。雖然 GDDR7 在訊號調變部分採用 PAM3,2 個符元傳輸 3 bit,相較與 Micron 合作開發 的 GDDR6X 採用 PAM4,1 個符元即傳輸 2 bit 來的少,但相對而言簡化後的實體層能夠降低耗電,運作時脈也會再次推升。
▼ Blackwell 在視訊記憶體部分將首採 GDDR7,使用 PAM3 調變。
延伸閱讀:CES 2025:GeForce RTX 50 系列報到,RTX 5090 – RTX 5070 桌機、筆電版逐步推出
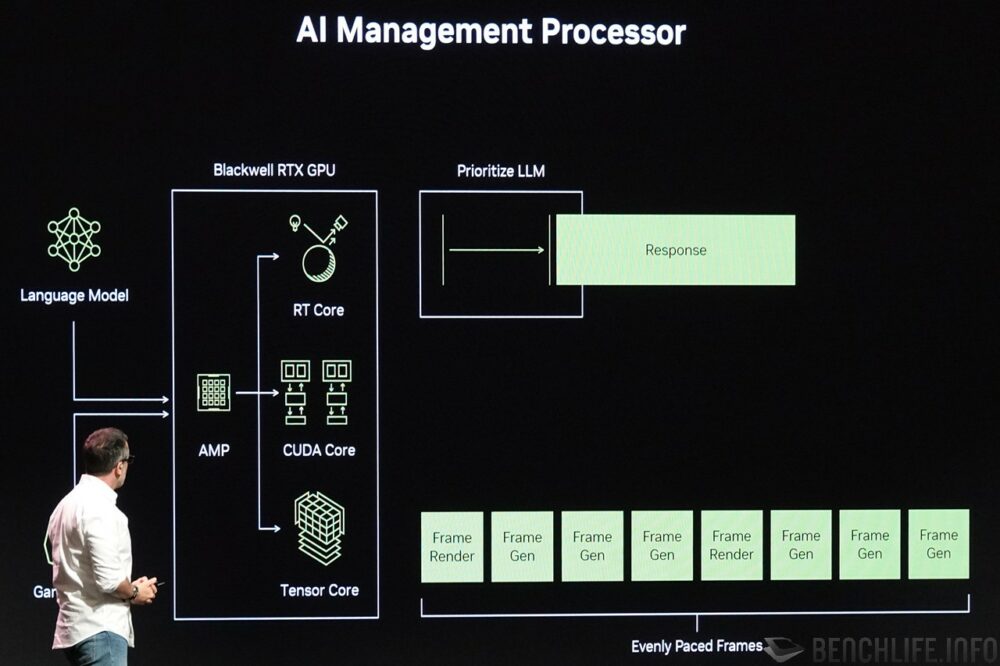
NVIDIA 預測到 AI 在遊戲內的應用越來越普及之時,該如何分配顯示卡內部多樣化工作的問題,如遊戲 AI 對話回應不可過慢、或是 DLSS Multi Frame Generation 每張畫面須擁有一致的生成時間…… 等,因此導入人工智慧管理處理器 AI Management Processor,可以根據現況調整不同作業的優先權,維持服務品質 Quality of Service。
▼ 人工智慧管理處理器 AI Management Processor 能夠依據現況調整運算作業的優先權,提升對話模型的反應速度,並提供一致的畫面生成時間。
提升電源效率
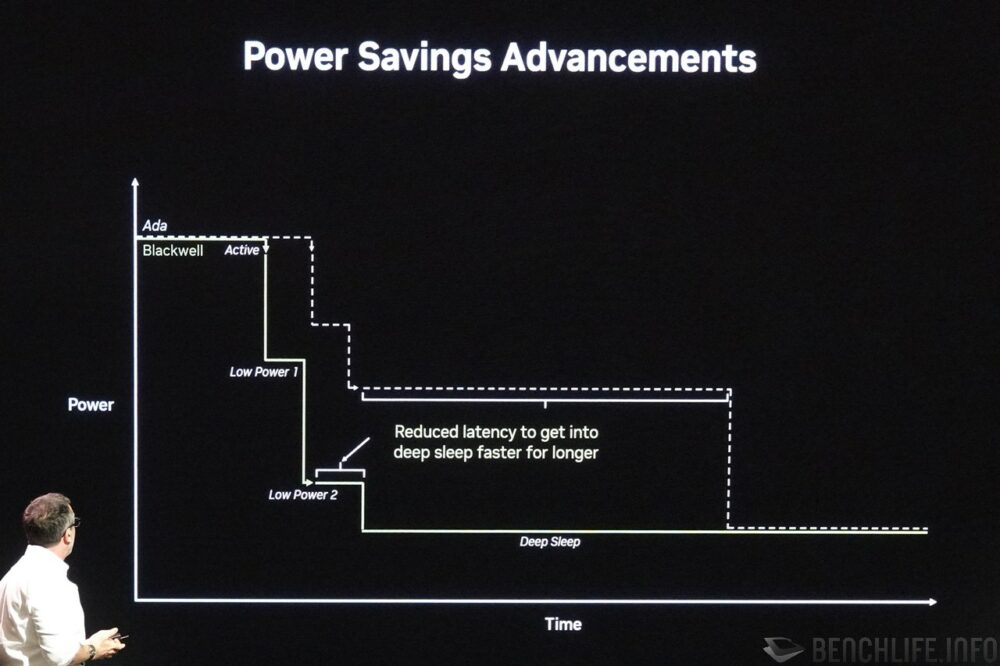
效能上的提升之外,Blackwell 同樣在電源效率上下了不功夫,且不僅止於筆記型電腦版本或是 Max-Q,GeForce RTX 50 系列桌上型版本同樣也享有這些福利。首先是針對閒置運算單元部分,原先已有時脈閘控 clock gating、電源閘控 power gating,Blackwell 再加入電源軌閘控 rail gating。
▼ Blackwell 新增電源軌閘控 rail gating,可單獨微調作業較不繁瑣區域的供電狀況。

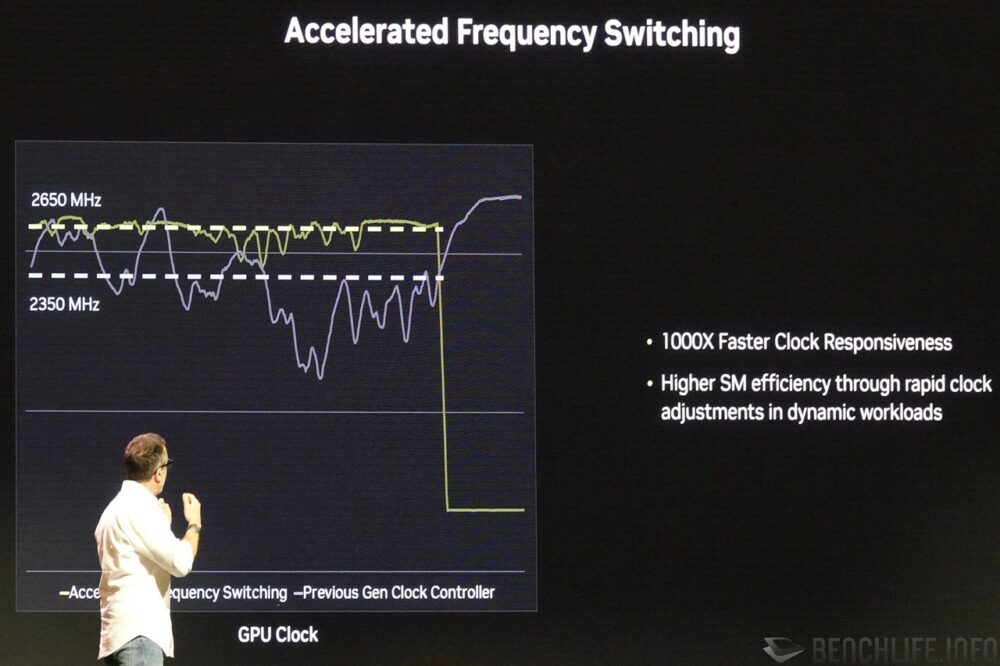
NVIDIA 號稱 Blackwell 時脈調整速度相較於 Ada Lovelace 快上千倍,進入低電源狀態的睡眠、喚醒速度也提升數個量級。由於時脈調整、進出低電源狀態的速度變快,如今就可以更為積極地調降時脈、進入低電源狀態,而不影響實際效能。NVIDIA 表示這不僅能夠節約 50% 的能量消耗(相較於 Ada Lovelace 進入深度睡眠的時間),同時也受惠於時脈調整速度,可以更快地迎合運算需求。
▼ Blackwell 時脈調整速度相較 Ada Lovelace 快上千倍,不僅能夠省電,也可以迎合突增的運算需求提供更佳的效能。
▼ 相較於 Ada Lovelace,Blackwell 進入深層睡眠的速度更快,相對而言可以省下 50% 能源消耗。
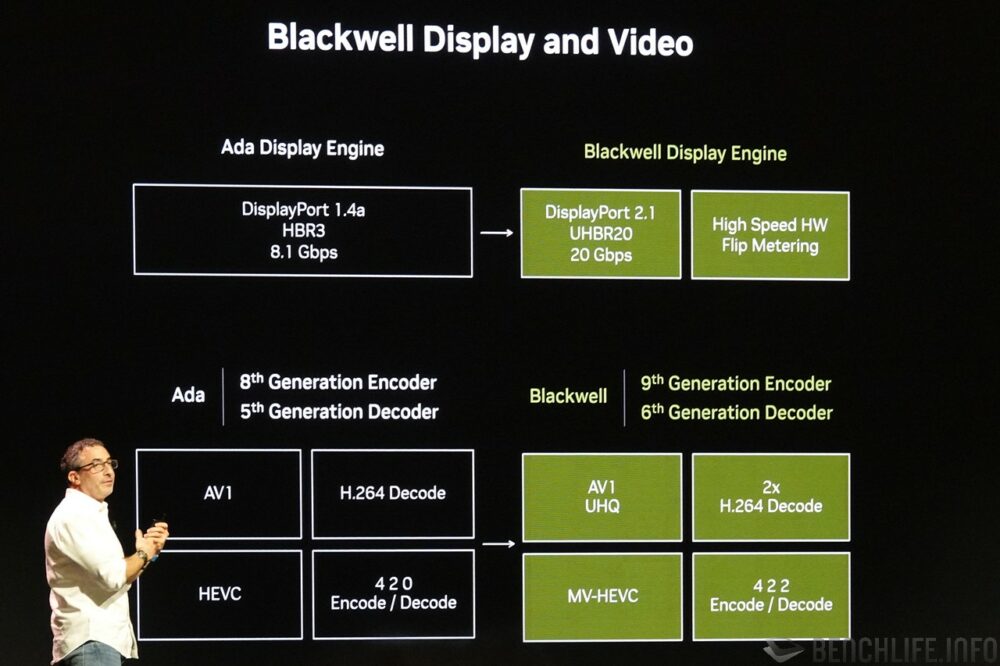
多媒體、顯示引擎更新
對於創作者而言,若是硬體支援視訊編碼作業,即可省下不小的 CPU 負擔,並加快創作問世的速度。GeForce RTX 50 系列雖說尚不支援已在 Intel 代號 Lunar Lake 上獲得支援的 VVC / H.266,卻也透過支援 MV-HEVC(Multiview-High Efficiency Video Coding)的方式將多視角影片納入旗下,AV1 支援性同時提升至 UHQ 超高畫質。(註:最高階 GeForce RTX 5090 共有 3 組第九代 NVENC、2 組第六代 NVDEC)
至於早已在 Intel 內建顯示多媒體引擎獲得支援的 4:2:2 色度取樣(YCbCr 比例),NVIDIA 終於在 Blackwell 世代當中提供支援,相較 4:2:0 紀錄更多色彩資訊,提升畫面品質。顯示輸出引擎同時升級至 DisplayPort 2.1 UHBR20,單一通道支援 20Gbps 頻寬,單一線材具備 4 通道即可達 80Gbps。用於檢測實際畫面輸出延遲的高速硬體 Flip Metering 也位於此,為多幀生成 Multi Frame Generation 提供數據回饋。
▼ GeForce RTX 50 系列在影片編碼、解碼器部分雖稱不上是大刀破斧,但總算是把 4:2:2 色度取樣納入了。
持續精進的 Founders Edition 散熱設計
自從 GeForce RTX 20 系列世代開始,俗稱的「公版卡」Founders Edition 就捨棄可以將顯示卡廢熱確實排出機殼,但噪音表現卻不慎理想的鼓風扇 blower 設計,陸續轉往一般的軸流風扇設計。GeForce RTX 30 系列之後更導入穿透式散熱鰭片設計,風流能夠直接吹過散熱鰭片不受到任何的阻擋。
直至 GeForce RTX 50 系列,Founders Edition 採用更為激進的作法,將主要乘載 GPU 封裝、記憶體、電源供應轉換的電路板設計得十分小巧,騰出空間裝上 2 組穿透式散熱設計,即便是應付 TGP 達 575W 的 GeForce RTX 5090,仍舊可以達成 2-slot 外形設計,並符合 SFF-Ready 規範,符合迷你電腦愛好者的需求。
▼ 掛上自家品牌進行銷售的 NVIDIA 顯示卡,其散熱器設計不斷更新。
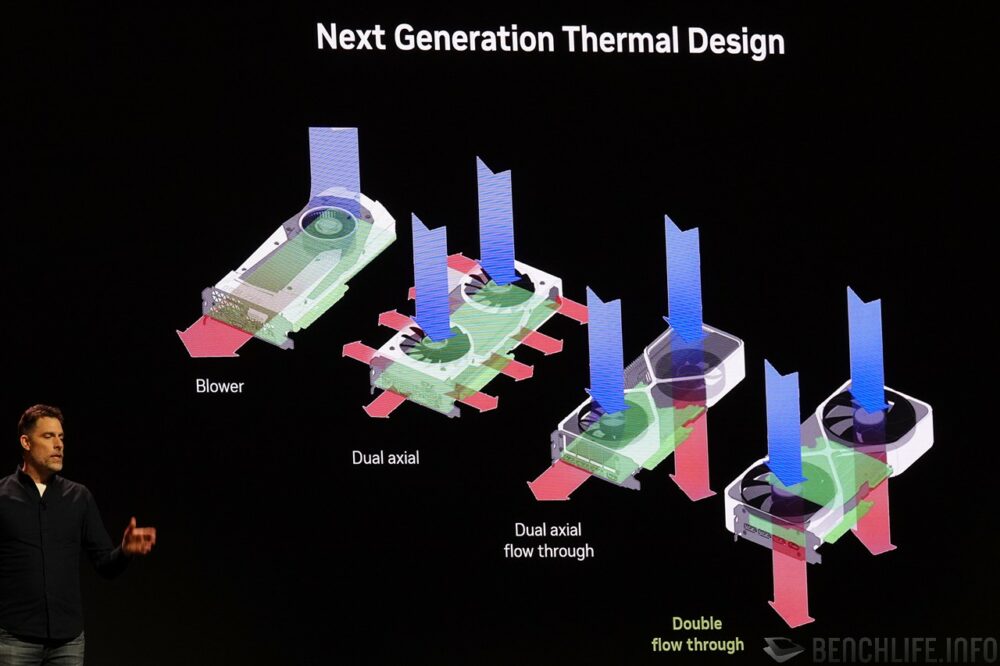
▼ GeForce RTX 5090 和 GeForce RTX 5080 兩者 Founders Edition 具備雙重穿透式散熱設計。

▼ GeForce RTX 50 系列與 GeForce RTX 40 系列、GeForce RTX 20 系列的重點比較。

對了,最後的重點,GeForce RTX 50 系列顯示卡仍舊採用 TSMC 4N 製程。