
AMD(NASDAQ: AMD)宣布推出AMD Instinct MI300X加速器。
為生成式人工智慧(AI)帶來領先業界的記憶體頻寬以及為大型語言模型(Large Language Model,LLM)訓練與推論提供領先效能。同時也推出AMD Instinct MI300A加速處理單元(APU),結合最新AMD CDNA 3架構與“Zen 4” CPU,為高效能運算(HPC)與AI工作負載帶來突破性效能。
AMD總裁Victor Peng表示,AMD Instinct MI300系列加速器以我們的最先進技術打造,帶來領先效能並能夠在大規模雲端與企業部署。透過我們的領先硬體、軟體與開放產業體系方案,雲端供應商、OEM與ODM正在推出技術,助力企業採用和部署AI解決方案。
微軟採用最新AMD Instinct加速器產品組合,近期宣布全新Azure ND MI300x v5虛擬機器(VM)系列,為AI工作負載進行最佳化並由AMD Instinct MI300X加速器挹注效能。此外,位在美國勞倫斯利佛摩國家實驗室(Lawrence Livermore National Laboratory,LLNL)的超級電腦El Capitan採用AMD Instinct MI300A APU,預期成為第二台搭載AMD核心的exascale等級超級電腦,可在完全部署時帶來超越2 exaflops的雙精度效能。Oracle Cloud Infrastructure(OCI)計劃新增基於AMD Instinct MI300X的裸機執行個體(bare metal instance)至其AI高效能加速運算執行個體。基於MI300X的執行個體與超快RDMA網路預計將支援OCI Supercluster。

各大OEM廠商也在AMD Advancing AI活動展示加速運算系統。戴爾科技集團展示採用8個AMD Instinct MI300系列加速器的Dell PowerEdge XE9680伺服器以及為生成式AI推出的全新Dell Validated Design,其搭配基於AMD ROCm的AI框架。HPE近期發表首款超級運算HPE Cray Supercomputing EX255a accelerator blade,搭載AMD Instinct MI300A APU,預期將於2024年稍早開始供貨。聯想宣布其設計支援全新AMD Instinct MI300系列加速器,計畫於2024上半年開始供貨。美超微(Supermicro)宣布其H13世代加速伺服器的全新產品採用第4代AMD EPYC處理器與AMD Instinct MI300系列加速器。
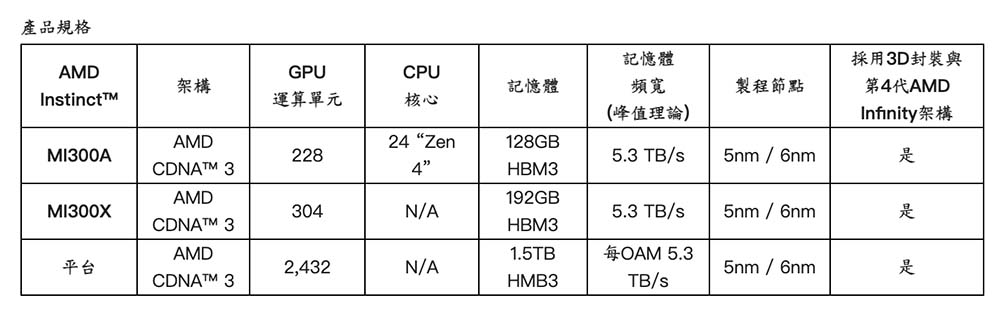
AMD Instinct MI300X加速器基於全新AMD CDNA 3架構。相較前一代AMD Instinct MI250X加速器,MI300X為AI與HPC工作負載帶來近40%的運算單元提升註2、高達1.5倍的記憶體容量提升以及高達1.7倍的峰值理論記憶體頻寬提升註3,同時支援FP8與稀疏性(sparsity)等的全新數學格式。
現今的LLM持續增加尺寸與複雜度,需要龐大的記憶體和運算能力。AMD Instinct MI300X加速器配備最優異的192GB HBM3記憶體容量以及每秒5.3TB的峰值記憶體頻寬,提供不斷增加且要求嚴苛的AI工作負載所需效能。AMD Instinct平台為領先生成式AI平台,奠基於產業標準OCP設計與8個MI300X加速器,提供領先業界的1.5TB HBM3記憶體容量。AMD Instinct平台的產業標準設計讓OEM合作夥伴可將MI300X加速器設計至現有的AI產品中並簡化部署,以及加速採用基於AMD Instinct加速器的伺服器。
相較NVIDIA H100 HGX,AMD Instinct平台在執行BLOOM 176B等LLM推論時提供高達1.6倍的吞吐量效能提升。此外,其為市場上唯一能夠在單個MI300X加速器上執行Llama2等70B參數模型的選擇,可簡化企業級LLM部署並帶來卓越的總擁有成本(TCO)。
AMD Instinct MI300A APU為全球首款為HPC與AI打造的資料中心APU,憑藉3D封裝技術與第4代AMD Infinity架構在HPC和AI交匯時提供領先的重要工作負載效能。MI300A APU結合高效能AMD CDNA 3 GPU核心、最新AMD “Zen 4” x86 CPU核心與新一代128GB HBM3記憶體,相較前一代AMD Instinct MI250X,在FP32 HPC與AI工作負載提供高達1.9倍的每瓦效能提升。
能源效率對HPC和AI社群至關重要,然而這些工作負載極其依賴資料和資源。AMD Instinct MI300A APU受益於將CPU與GPU核心整合到帶來高效率平台的單一封裝,同時為加速訓練最新的AI模型提供運算效能。AMD正以30×25目標為能源效率開創創新途徑,計劃從2020年至2025年間將用於AI訓練與HPC的伺服器處理器與加速器能源效率提升30倍。
APU優勢代表AMD Instinct MI300A APU搭配統一記憶體與快取記憶體資源可為客戶帶來簡易的程式化設計GPU平台、高效能運算、快速的AI訓練以及優異的能源效率,以應對要求最嚴苛的HPC和AI工作負載。
AMD宣布推出最新AMD ROCm 6開放軟體平台,這也體現公司向開源社群貢獻最先進的函式庫之承諾,推動AMD開發開源AI軟體的願景。ROCm 6軟體代表AMD軟體工具重大提升的一步,相較前一代硬體與軟體,其在MI300系列加速器執行Llama 2 text generation時帶來高達8倍的AI加速效能提升註7。此外,ROCm 6為FlashAttention、HIPGraph與vLLM等多個生成式AI全新關鍵功能新增支援。AMD位居獨特優勢,可透過Hugging Face、PyTorch與TensorFlow等最受廣泛使用的開源AI軟體模型、演算法與框架,驅動創新、簡化部署AMD AI解決方案與釋放生成式AI的真正潛力。
AMD也透過收購Nod.AI與Mipsology持續投資軟體能力,同時藉由Lamini、MosaicML等策略產業體系合作夥伴關係,為企業客戶執行LLM,以及憑藉AMD ROCm即可於AMD Instinct加速器執行LLM訓練,且毋須變動程式碼。


