
NVIDIA 採用 Ampere 架構的第二代 RTX 光追顯示卡 GeForce RTX 3000 系列,已於前幾天的時候正式發表,在效能相較 GeForce RTX 2000 系列幾近翻倍的情況下,MSRP 建議售價與前一世代相同,Founders Edition 也沒有另外加上信仰稅,如果台灣沒有出現神奇的匯率,確實是一大亮點,前浪還沒到沙灘上就已經提前宣布陣亡。
已發表的 GeForce RTX 3090/3080/3070 系列顯示卡,晶片製程從 TSMC 12nm FFN 轉換至 Samsung 8N(N 都是指 NVIDIA 客製製程的意思),雖然數字少了 1/3,但是目前各家晶圓代工廠的製程無法直接比較,Samsung 8nm 其實是 10nm 的改良版(TSMC 12nm 更是上古 16nm 的改良版)。即便如此,NVIDIA 還是在更小的晶片面積之中塞入 28 億個電晶體(GA102)。
整體而言,價格和效能的亮點,蓋過了 Ampere 架構的關注度,事實上 Ampere 相較 Turing 並沒有大修大改,微幅提升 IPC、運作時脈,以及堆疊電晶體/單元數量,就能夠成就 GeForce RTX 3080 於 4K 解析度下為 GeForce RTX 2080 的 2 倍效能。對了,也不能忘記 GA102 搭配的 GDDR6X 記憶體,介面訊號從 NRZ 變更為 PAM4,每個符元從 1bit 提升至 2bit,相同頻率的介面頻寬直接翻倍。
▼GDDR6X 每個符元從表示 1bit(2 種狀態)升級為 2bit(4 種狀態),同頻率的頻寬直接翻倍,同時也對佈線品質有著更高的要求。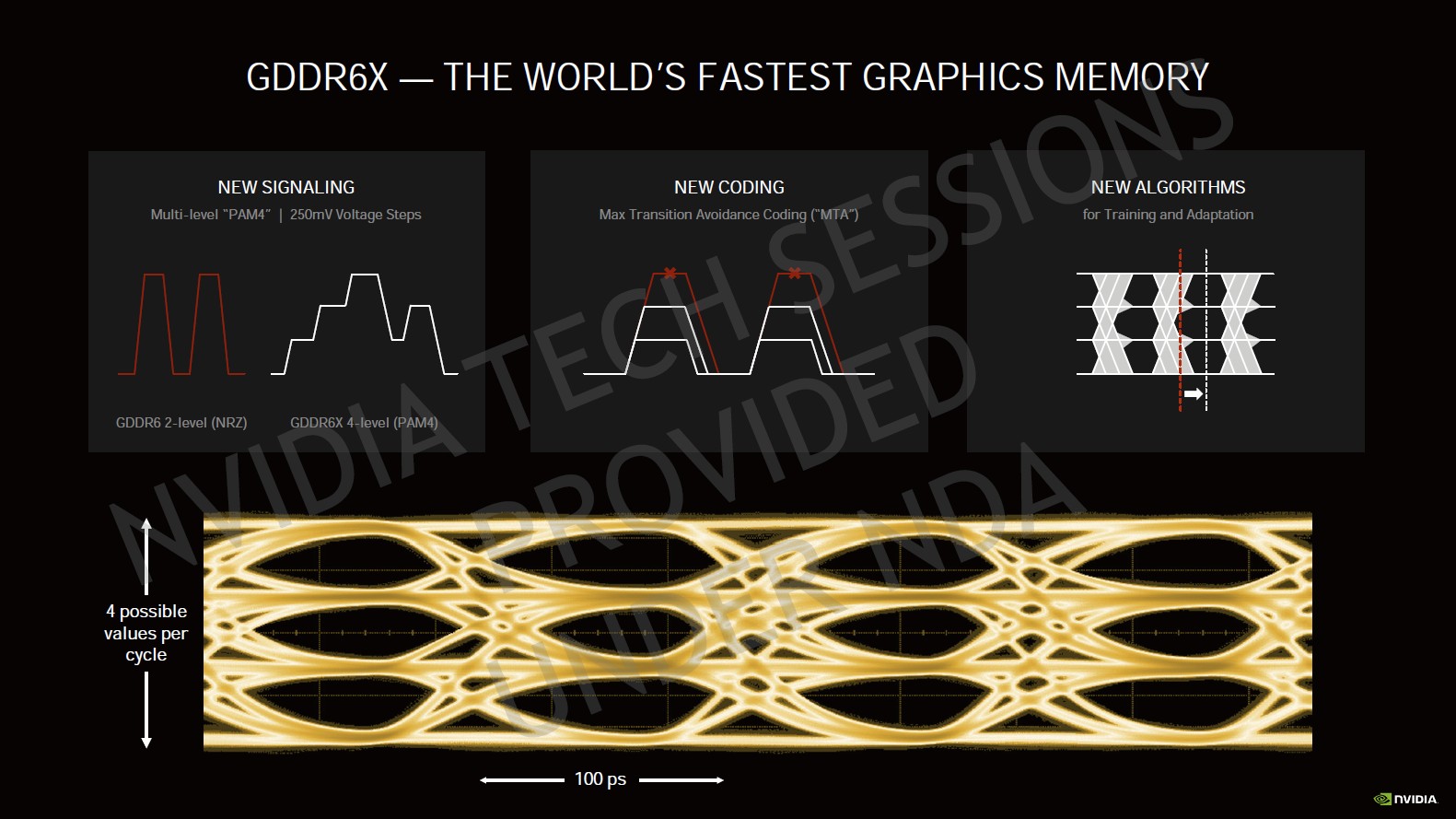
▼雖然 Ampere 架構內部的 SM、RT、Tensor 單元都是新的,但主要變化都建立在更大的電晶體規模,與 Turing 架構相比沒有太大的更動。
FP32 運算單元翻倍
Ampere 每個 TPC(Texture Processing Clusters)內部仍然有 2 組 SM(Streaming Multiprocessor),但是每個 GPC(Graphics Processing Clusters)內部 TPC 數量,從 Turing 的 4 組增為 6 組。SM 內部 L1/材質快取大小從 96KB 提升至 128KB、頻寬加倍,最大可分割的分區大小也加倍。
Turing SM 內部 INT32 整數運算單元和 FP32 浮點運算單元各自獨立,Ampere 則是替 INT32 單元也加上了 FP32 處理能力,讓這個單元能夠執行 INT32 或是 FP32 運算;簡言之,就是每個 SM 的 FP32 峰值效能達到以往的 2 倍,單一時脈週期可執行 128 個 FMA 運算。
▼Ampere 的 SM 經過改良,多個關鍵性指標效能可達 Turing 的 2 倍。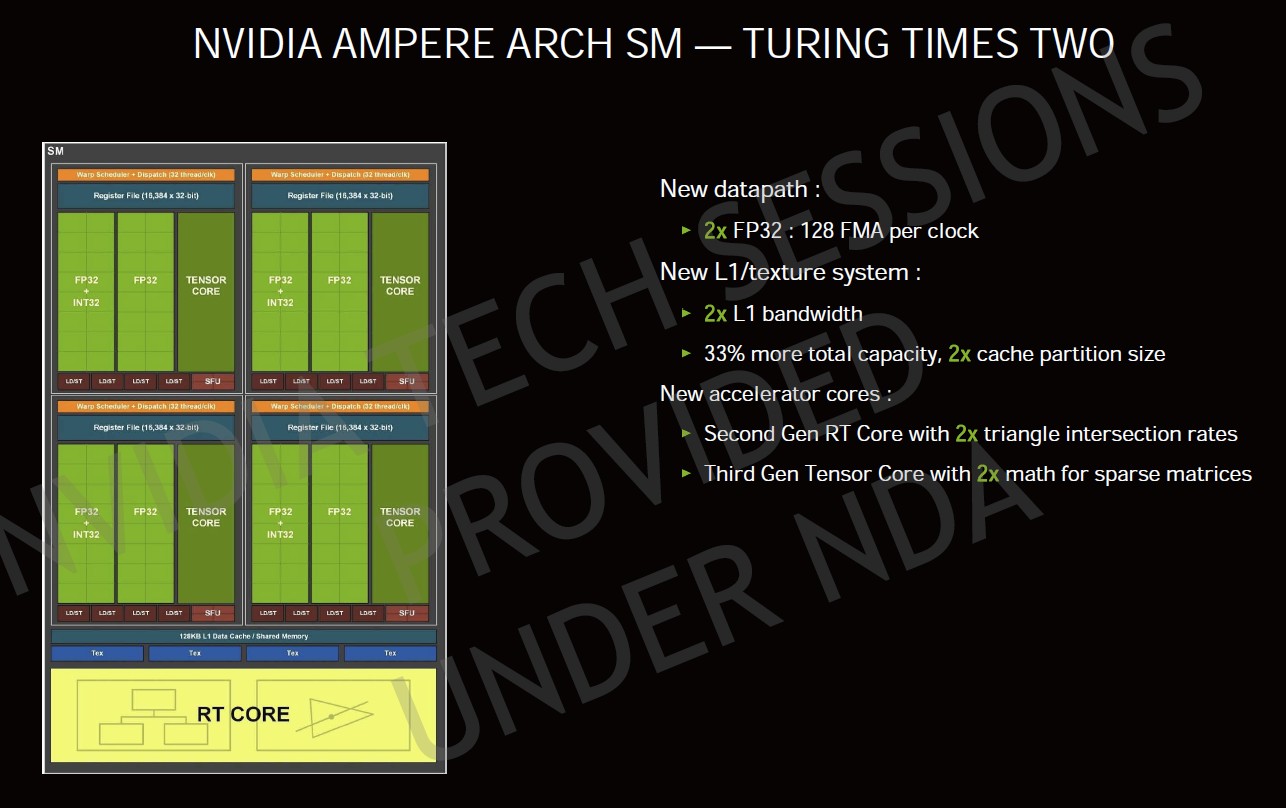
談到光線追蹤演算法,目前比較流行的是 BVH(Bounding Volume Hierarchy)遍歷,將空間當中的三角形物件資訊以樹狀資料結構編排,一步步查看光線究竟打到哪個物件三角形表面,Turing 架構新增的 RT 核心就是用來執行這個耗時、擁有許多遞迴的演算法。
Ampere 架構的 RT 核心為第二代設計,可以提供 2 倍的三角形相交檢測效能,除此之外還針對 Motion Blur 動態模糊提供以時間為變因的 Interpolate tri position 3 位插值功能,相較過往沒有這功能的 Turing RT 核心,光線遍歷效能高達 8 倍以上。
▼Ampere 架構採用第二代 RT 核心,除了強化 BVH 遍歷性能之外,另外替動態模糊特效場景加入 Interpolate tri position(Time)功能。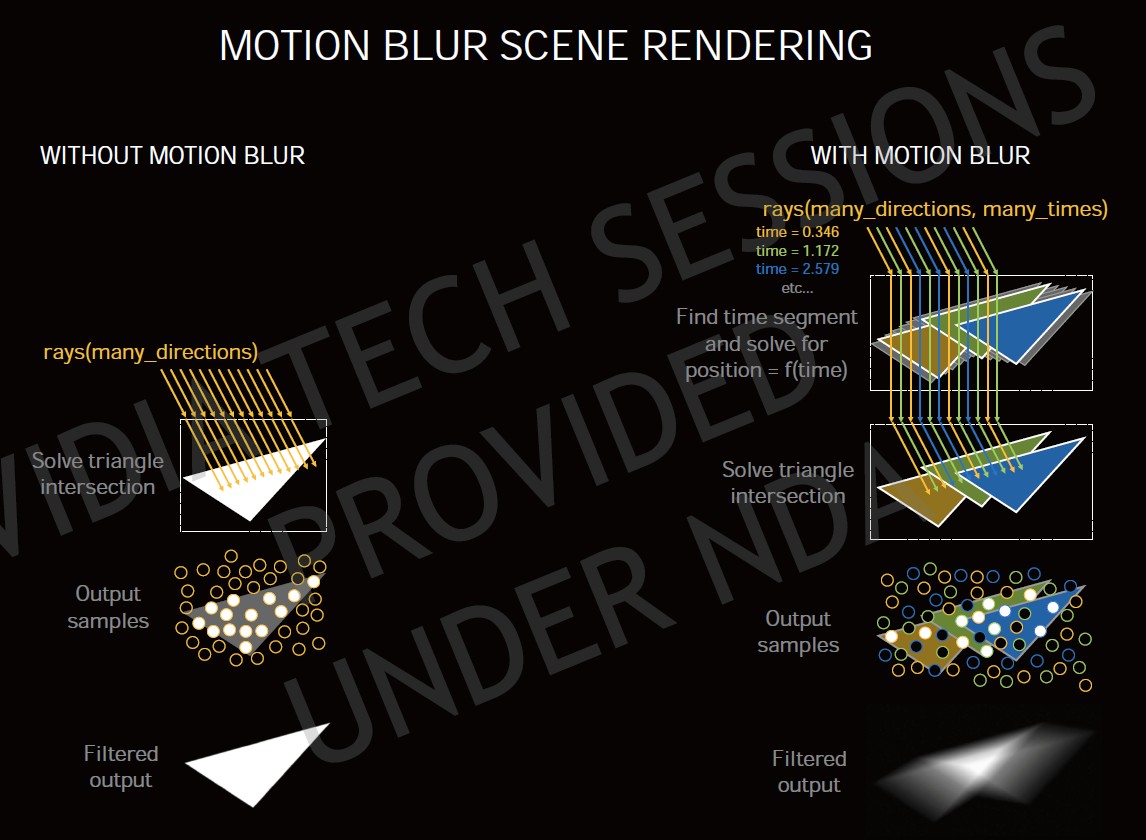
Tensor 支援稀疏矩陣
Ampere Tensor 核心是比較棘手的地方,雖然第三代核心(第一代在 Volta 身上、第二代在 Turing 身上)效能提升 2 倍,但每個 SM 的 Tensor 核心單元數量從 8 個減半至 4 個;即便計入更多的 SM、更高的時脈,Ampere Tensor 整體運算效能相較 Turing Tensor 成長幅度約在 30% 左右。
關鍵之處在於第三代 Tensor 核心支援 sparse matrix 稀疏矩陣,也就是矩陣當中有許多元素為 0 的狀態,可以透過資料結構壓縮、調整演算法加速運算。NVIDIA 比較了 Turing 世代 TU102 和 Ampere 世代 GA102,每個 SM 內部的 Tensor 核心執行 FP16 FMA 的效能相等,但第三代 Tensor 可透過支援 sparse matrix 將效能拉高至 2 倍。
▼Ampere 所擁有的第三代 Tensor 雖然擁有第二代的 2 倍,但 SM 內部實際核心單元數量減半,主要透過支援 sparse matrix 將整體效能拉高至 2 倍。
最後則是顯示輸出與固定功能單元的改進,Ampere 為第一個支援 HDMI 2.1 規範的 GPU,能夠透過單一纜線輸出 8K@60Hz 或是 4K@120Hz 視訊畫面,此外影片硬體解碼單元新增 AV1,解碼效能可達 8K60。
▼Ampere 支援 HDMI 2.1,單一纜線即可輸出輸出 8K@60Hz 或是 4K@120Hz,並新增支援至 8K60 的 AV1 格式硬體解碼。
依據 NVIDIA 的資料,Ampere 世代晶片設計將電源供應切成 2 大區塊,繪圖區自成 1 個區塊,其餘系統、記憶體控制器……為另外 1 個區塊,加上 Samsung 8N 製程加持,在遊戲效能表現固定於 60FPS 的前提之下,Turing 架構需花費 240W,Ampere 架構大約僅有 120W 出頭,能源效率比值提升 1.9 倍左右,且 Ampere 架構效能還可以再往上飆。
▼Ampere 世代晶片設計將電源供應切成 2 大區塊,且相較 Turing 架構的能源校約提升至 1.9 倍。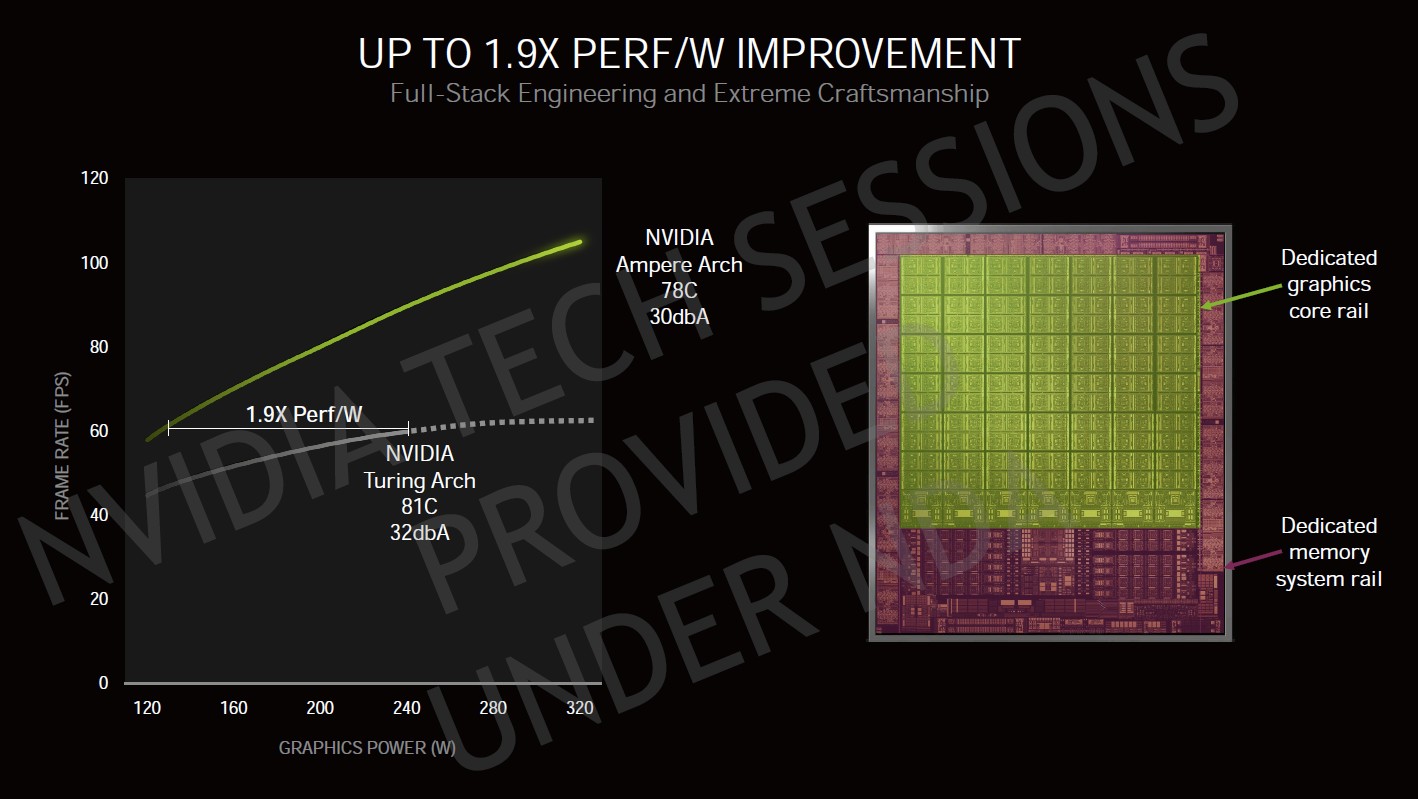
遊戲效能翻倍
由於 Ampere SM 內部的 INT32 運算單元也能夠處理 FP32,因此這個世代的 CUDA 數量以暴增來形容也不為過,GeForce RTX 2080 僅有 3072 個 CUDA,GeForce RTX 3080 則有 8704 個,幾乎達到 3 倍!實際而言,即便 FP32 峰值效能將因為插入一些 INT32 運算而有所下滑,多款遊戲測試仍有不錯的效能加成。
另一方面,Ampere 架構也支援 RT 核心與 Tensor 核心運算工作同步執行,每幀的運算延遲時間能夠從 Turing 架構的 7.5ms 縮減至 6.7ms。
▼經過 2 年的沉潛,Ampere 世代相較於 Turing 世代的遊戲效能提升許多。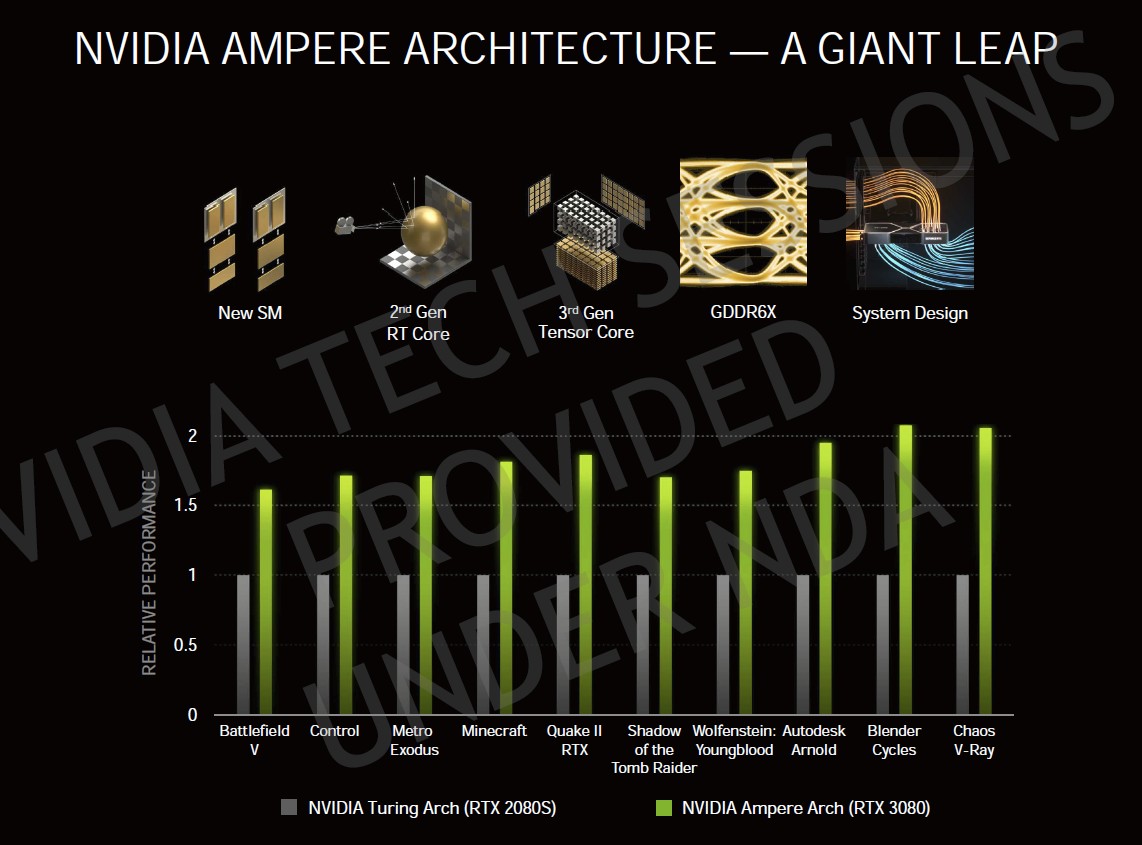
▼GeForce RTX 3080 GA102 的規格資訊,看來滿血紫裝為 10752 個 CUDA。
▼如今 Ampere 架構的 RT 核心和 Tensor 核心也能夠同步運算,將每幀的運算延遲時間再次縮小。


