NVIDIA推出新版本的預先訓練模型,以及遷移學習工具套件 (TLT) 3.0 正式推出的版本。
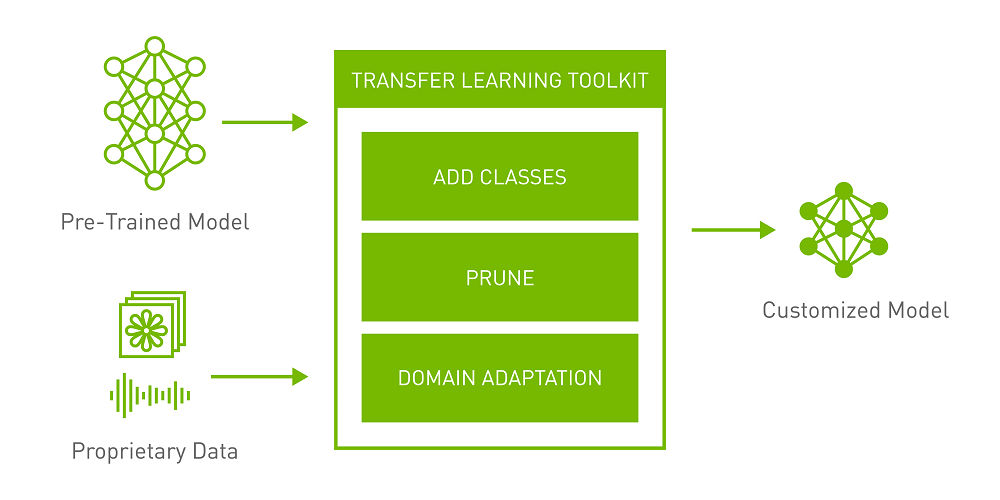
NVIDIA (輝達) 宣布推出新版本的預先訓練模型,以及遷移學習工具套件 (TLT) 3.0 正式推出的版本,這是以 NVIDIA 的 TAO (Train, Adapt and Optimize) 平台引導工作流程以打造人工智慧 (AI) 的核心要素。此版本包含用於電腦視覺及對話式 AI 領域的多種高精度且高效的預先訓練模型,以及一組強大的生產力功能,能以最高達十倍的速度開發 AI。
在企業都搶著將有 AI 支援的解決方案推向市場之際,是否能取得最好的開發工具就決定了企業競爭力。對於許多試圖使用開源碼模型進行訓練,以開發出 AI 產品的工程和研究團隊來說,想要在生產環境中部署客製化、高精度、高效能 AI 模型的開發歷程,可能是件變化莫測的事。NVIDIA 提供高品質的預先訓練模型和 TLT,協助減少大規模資料收集與標註的成本,還能免除從零開始訓練 AI 或機器學習模型的工作。剛進入電腦視覺和語音服務市場的業者,現在無需龐大的 AI 開發團隊,也能夠部署生產級的 AI。
新版本中的亮點有:
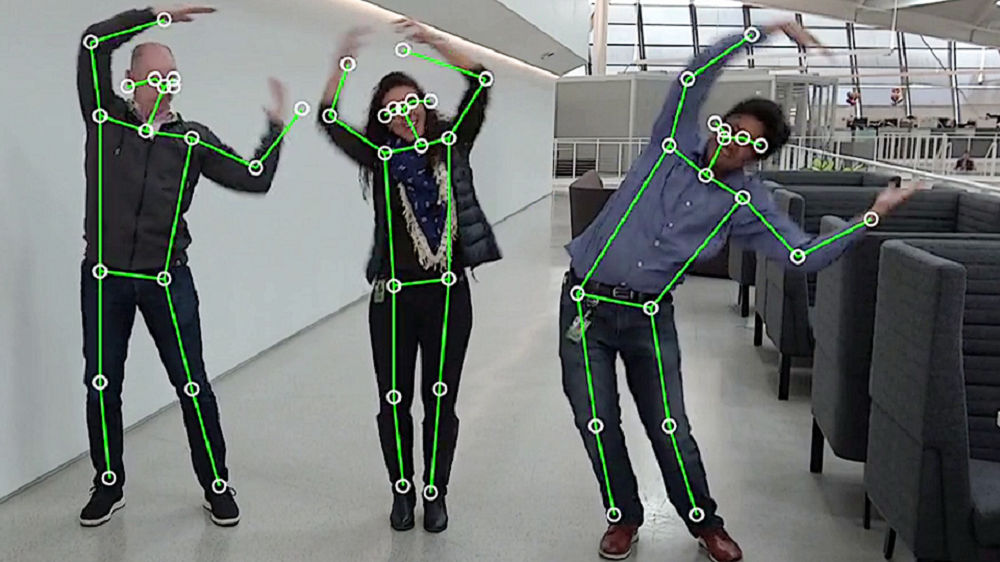
- 一個支援邊緣即時推論的姿勢預測模型,推論效能比 OpenPose 模型快九倍。
- 用於人員偵測的語義分割網路 PeopleSemSegNet。
- 用於多種產業應用案例的多種電腦視覺預先訓練模型,像是車牌偵測和辨識、心率監測、情緒辨識、人臉特徵點等。
- 在多種特定領域及開源碼資料集上進行訓練的全新語音辨識模型 CitriNet。
- 用於問答的全新 Megatron Uncased 模型,和多種支援語音轉文字、命名實體辨識 (named-entity recognition)、標點符號及文字分類的預先訓練模型。
- 可在 AWS、Google Cloud Platform 和 Azure 上進行訓練。
- 在 NVIDIA Triton™ 與 DeepStream SDK 上開箱即能部署視覺型 AI,和在 Jarvis 上開箱即能部署的對話式 AI。
快速開始使用
整合資料生成及標註工具,以更快速、精準地開發 AI
TLT3.0 還與多個頂尖合作夥伴的平台進行整合,這些合作夥伴提供大量、多樣化、高品質的標記資料,以便更快地執行端到端的 AI 及機器學習工作流程。現在已能使用這些合作夥伴的服務來生成和標註資料、與 TLT 無縫整合以進行模型訓練和最佳化,並使用 DeepStream SDK 或 Jarvis 來部署模型,建立可靠的電腦視覺和對話式 AI 應用程式。
Tags: NVIDIA