快取就是要大、大才有效!
這次 AMD 推出採用 RDNA 2 架構的 Radeon RX 6000 系列顯示卡,可說是徹底地揚眉吐氣,該公司不僅是在 x86 處理器效能徹底贏過競爭對手 Intel,Radeon RX 6000 系列相較 NVIDIA GeForce RTX 3000 系列也是相當具有競爭力,突破過去僅能在中階主流市場對打的情況。
仔細端詳 RDNA 2 和 RDNA 內部 CU(Compute Unit)差異,除了增加 DXR(DirectX Raytracing)必須的 Ray Accelerator 光線加速器單元之外,並沒有什麼變化,小修小改傳輸路徑與快取機制、強化 power gating 省電機制、提升時脈頻率,讓 RDNA 2 的 IPC 相較 RDNA 僅有個位數的成長。那麼接下來你會問,能夠幹掉 GeForce RTX 3090 的效能是從哪裡來的?
▼ RDNA 2 三大主軸:更高的運作時脈、Infinity Cache、支援最新的 DirectX 12 Ultimate 和 DirectStorge API 功能。
如同 NVIDIA Ampere 世代,加入浮點數執行功能至原本的 INT 整數執行單元,直接讓 CUDA/Stream Processor 數量暴增,RDNA 2 世代 Navi 21 晶片設計,同樣也從前一世代 Navi 10 的 40 個 CU/2560 個 Stream Processor,翻倍暴增到 80 個 CU/5120 個 Stream Processor(Radeon RX 6900 XT 採用完全體,其餘型號依序遞減數量),這也讓持續採用 TSMC 7nm 製程的情況之下,晶片面積與電晶體數量,從 251mm2/103 億個成長至 519mm2/268 億個。
▼ RDNA 2 使用 TSMC 7nm 製程,並添加 AV1 硬體解碼與 8K HEVC 編碼能力。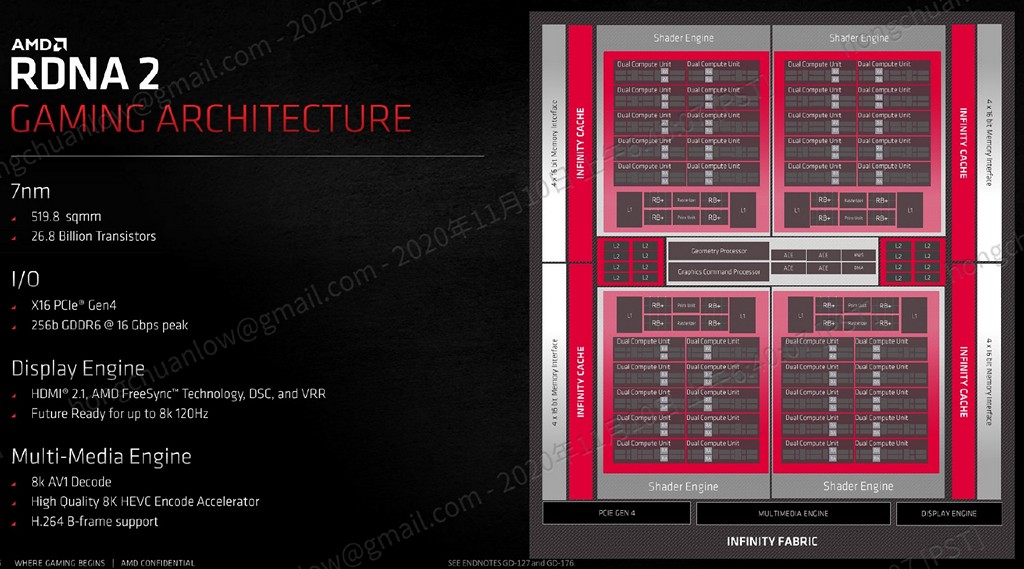
▼ 執行單元與快取的細部資訊。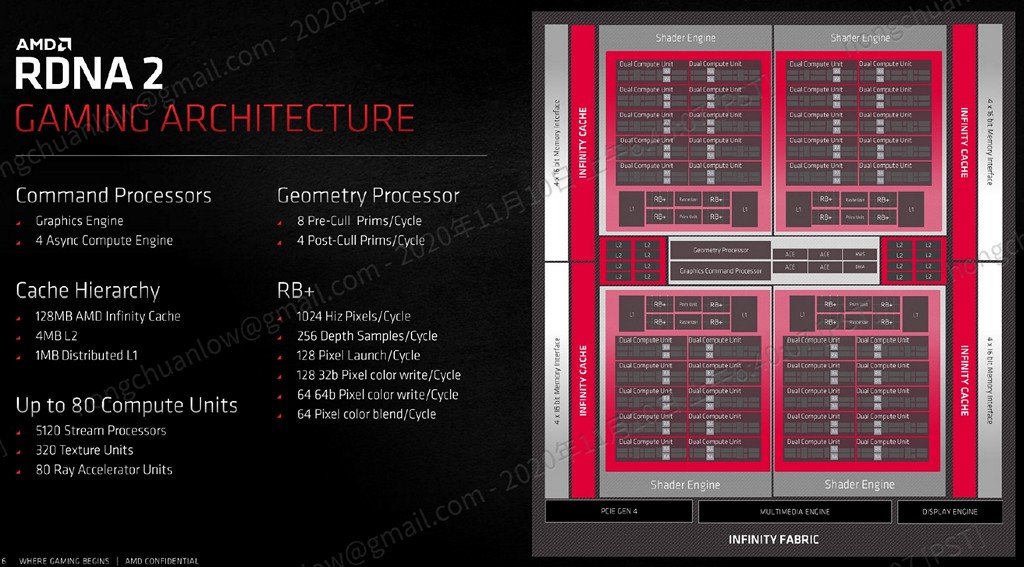
▼ AMD 替每個 CU 均添加 1 個光線加速器單元,因此 RDNA 2 的光線追蹤單元數量跟著 CU 變動,Radeon RX 6900 XT 為 80 個、Radeon RX 6800 XT 為 72 個、Radeon RX 6800 為 60 個。
▼ RDNA 2 CU 面對不同類型資料的運算能力,每個時脈能夠執行 4 個 bonding box 或是 1 個光線與三角形的相交檢測。
▼ 每組 Shader Engine 的 RB+ 為全新設計,單一時脈週期能夠處理 8 個 32bit 色深像素,並與光柵單元連動提供 2×1、1×2、2×2 取樣支援。
128MB Infinity Cache
Stream Processor 數量成長,相對而言需要餵給執行單元更多的指令、資料,NVIDIA 採用與 Micron 合作 GDDR6X 繪圖記憶體加大頻寬。AMD 目前已確立運算、繪圖架構分立路線,運算交由 CDNA 系列搭配 HBM 類型記憶體負責,消費市場端應該不會再出現 Radeon VII 這樣的產物,在亟需頻寬的情況之下,直接在 Navi 21 晶片設計高達 128MB 的 Infinity Cache,Radeon RX 6800/6800 XT/6900 XT 各等級均可享用。
▼ Navi 21 晶片設計於 GDDR6 記憶體和 L2 快取之間,添加容量為 128MB 的 Infinity Cache。
▼ 快取太小沒意義,太大又會讓晶片過胖,衡量快取命中率與容量的關係式之後,128MB 是個比較適中的容量。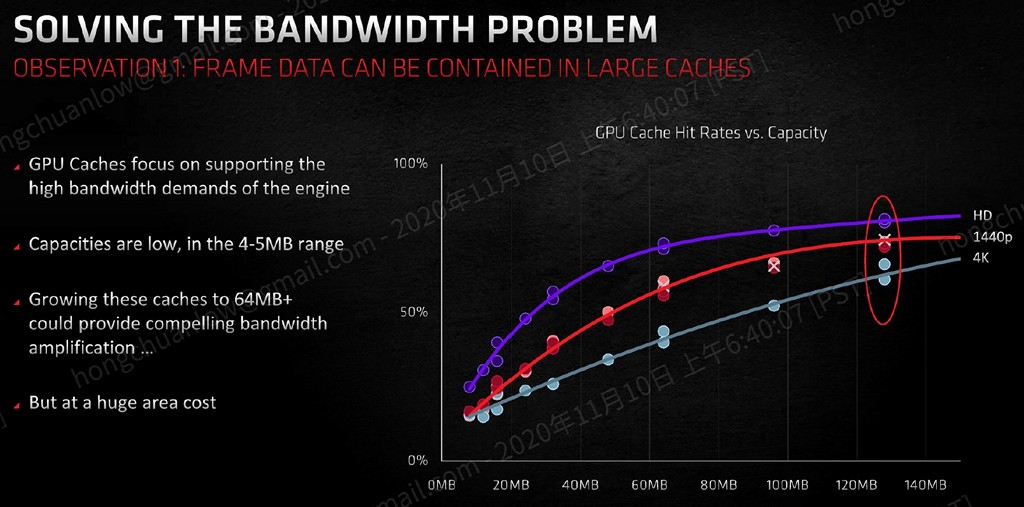
Navi 21 仍舊採用 GDDR6 記憶體,匯流排寬度 256bit,搭配 16Gbps 速度版本時,可以提供 512GB/s 頻寬,Radeon RX 6800/6800 XT/6900 XT 全線均提供 16GB 記憶體容量。128MB 的 Infinity Cache 在晶片內部的匯流排寬度為 64byte x 16 通道,在最高自動加速頻率達 1.94GHz 的狀況下,能夠提供將近 2000GB/s 頻寬(基礎頻率則可提供 1664GB/s),相當驚人!
▼ Infinity Cache 採用動態時脈設定,最高可達 1.94GHz,提供將近 2000GB/s 頻寬。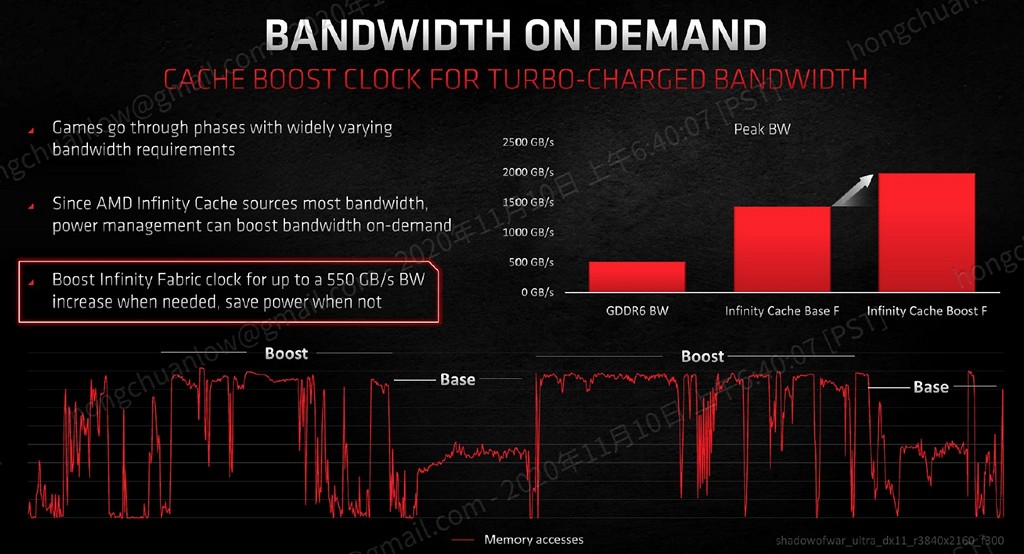
由於這個 128MB Infinity Cache 的出現,才能夠餵飽飢腸轆轆的 5120 個 Stream Processor,也一舉讓 RDNA 2 擁有相當不錯的能源效率比值。除了傳統上的光柵化成像之外,128MB 容量也能夠擺放光線追蹤所必需的 BVH 樹狀資料結構,有助於加速光線與三角形的相交檢測,這個極度消耗晶片面積的 Infinity Cache 也算是值得了。
▼ 於圖片最左方能夠觀察到,若是沒有添加 Infinity Cache,其實 RDNA 2 相較於 RDNA 的 IPC 漲幅並不明顯。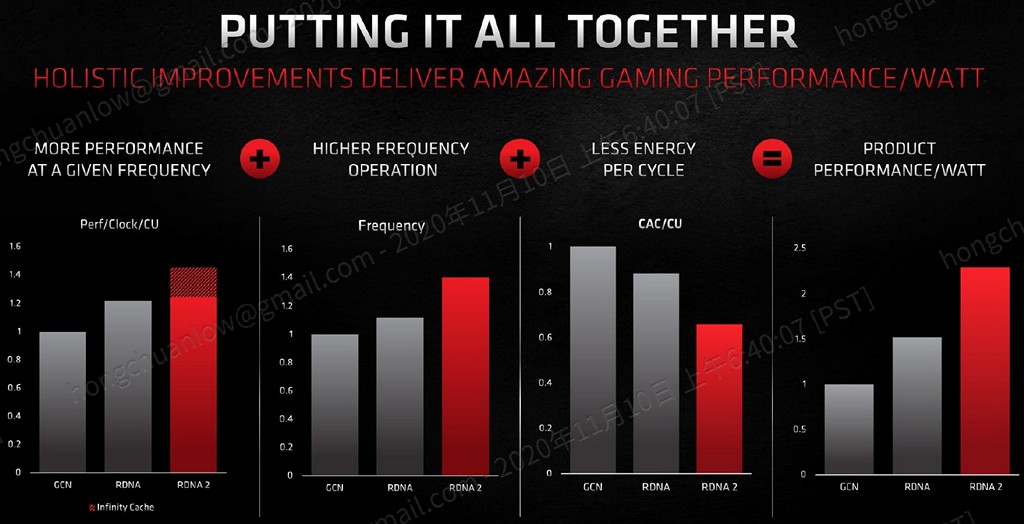
▼ Infinity Fabric 不僅提供驚人的頻寬,相對而言更能提升能源效率比值、降低存取延遲。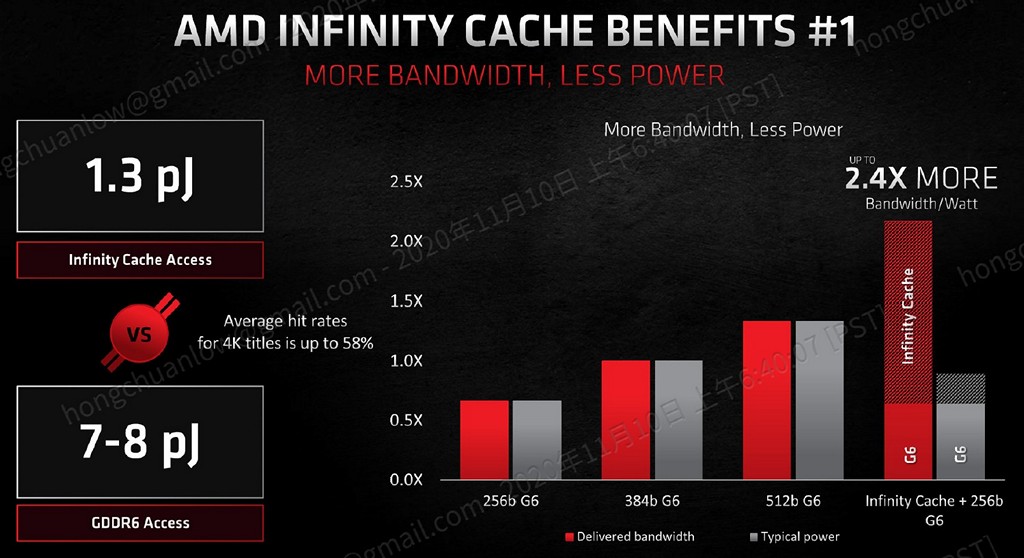
RDNA 2 架構也終於加入包含光線追蹤、VRS 可變速率著色(Tier 2)、Mesh Shader 網格著色器、Sampler Feedback 取樣回饋等 DirectX 12 Ultimate 功能。其實 AMD 這部分走得相當緩慢,甚至比 Intel 還要慢,Intel 早已在代號 Ice Lake 處理器的 Gen 11 繪圖核心支援 VRS,AMD 直到 RDNA 2 才算是全面導入。
▼ RDNA 2 已全面支援 DirectX 12 Ultimate。
Smart Access Memory
另一方面,AMD 終於提供 3A 平台(處理器、主機板的晶片組、顯示卡)合體加速特性,當支援的硬體相互搭配,能夠開啟所謂的 Smart Access Memory 功能,再次提升遊戲效能。縱使 AMD 於發表 Radeon RX 6000 系列顯示卡當下並未提供詳細技術資訊,之後輾轉得知其實就是 Resizable BAR 功能。
PCI 規範當中,需要每個設備自行準備 256Byte 的 Configuration Register Space,前 64Byte 儲存這個設備的 Device ID、Vender ID 等基礎資訊,後 192Byte 則是描述這個裝置究竟有什麼功能,到了 PCIe 時代,這個 256Byte 空間擴展至 4KB。處理器無法直接存取這些額外的 4KB-256Byte 空間,而是透過記憶體位址映射的方式,從高位址往下映射空間,處理器僅需讀寫這些映射空間,實際 PCIe 設備空間操作則由 PCIe Root Complex 負責。
BAR 為 Base Address Register 的縮寫,也就是 PCIe 設備空間映射到系統記憶體的基底位址,一般來說為保持與 32 位元作業系統的相容性,BAR 通常為 256MB(1 個 PCIe 系統最多擁有 256 條 Bus、每條 Bus 最多擁有 32 個設備、每個設備最多擁有 8 個功能,每個功能對應 1 個 4KB 範圍,256 x 32 x 8 x 4KB=256MB)。256MB 記憶體映射通常在 64bit 作業系統當中不會有什麼問題,因為記憶體控制器根本無法完整定址 264 實體記憶體;但在比較老舊的 32bit 作業系統,你可以發現並無法完整用完 232=4GB 實體記憶體,因為部分位址已拿去作為設備 I/O 或是記憶體空間映射用途。
▼ Smart Access Memory 應該就是 PCIe 規範裡的 Resizable BAR 功能,讓處理器可以同時存取顯示卡所有的記憶體,而非預設的 256MB。
為保持相容性,目前在記憶體位址中切給 PCIe BAR 的空間也都保持 256MB,但其實 BAR 能夠增加它的範圍大小,也就是 AMD 所說的完全存取顯示卡所搭載的記憶體,而非僅限於 256MB。依據 AMD 內部的實際測試,若是啟用 Smart Access Memory,最高能夠在 Forza Horizon 4 遊戲獲得 11% 的效能提升。此舉也讓綠色陣營額外表示,它們的晶片其實也支援 Resizable BAR 功能,未來會透過軟體更新開放。
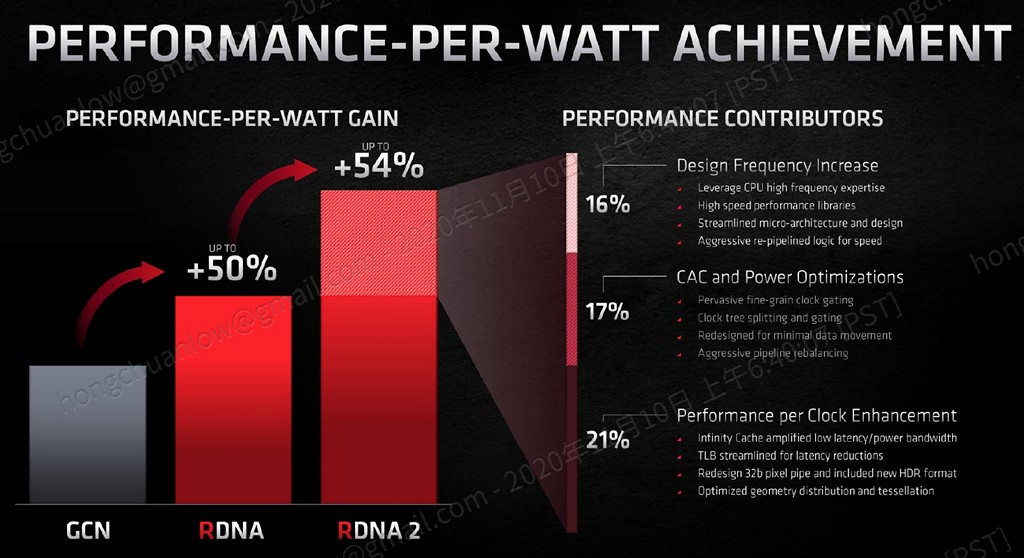
▼ RDNA 2 能源效率比值相較 RDNA 提升約 54%,其中 21% 透過 Infinity Cache 與微調設計提供、17% 為強化省電設計、16% 為提升運作頻率。