
Intel 消費性平台消失的 AVX-512,以全速之姿在 AMD Zen 5 微架構當中復活了!
在正式進入 Zen 5 微架構之前,我們希望先行提到製程的二三事。
此次 Zen 5 微架構的推出,在製程方面搭配 TSMC N4(桌上型處理器版本)∕ N3(行動處理器版本);特別是桌上型處理器版本,製程演進並不若 Zen(GF 14nm)> Zen 2(TSMC N7)或是 Zen 3(TSMC N7)> Zen 4(TSMC N5),N4 算是 N5 的強化版本,在 TSMC 的規劃中並非完整的製程世代躍進。有了這個先決條件之後,讀者可以思考一下 AMD 是如何去強調 Zen 5 和 Zen 4 之間的差異。
延伸閱讀:
AMD Zen 4 微架構詳解,平台全面升級再加贈 AVX-512
IPC 效能提升 19%!AMD x86 處理器 Zen 3 微架構改進詳解
執行單元變多、變寬
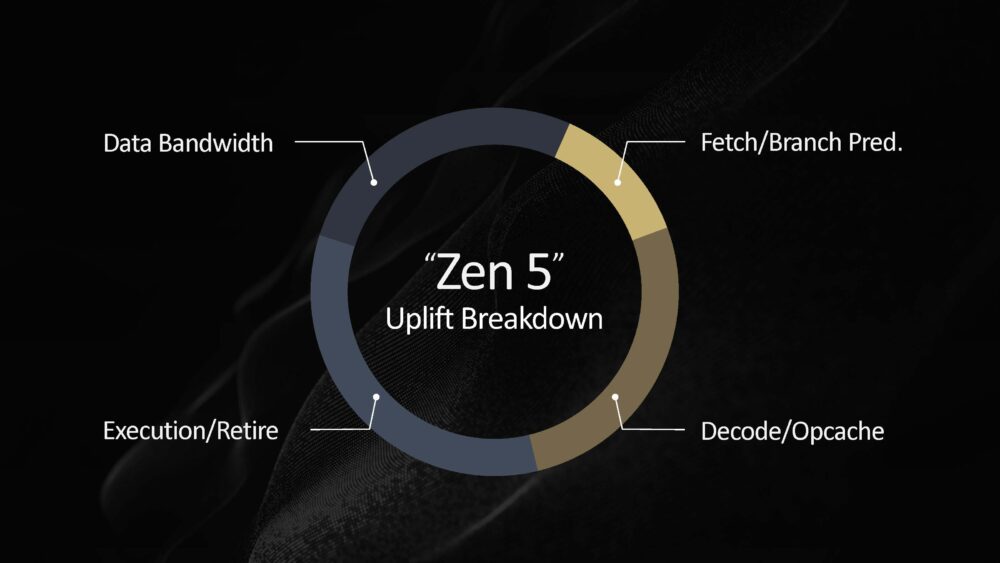
相較於先前多個 Zen 微架構的世代演進,AMD 這次在 Zen 5 微架構的著墨上少了許多至少 PPT 就少了好多頁,最主要的變化集中在執行單元的數量以及寬度。就 AMD 內部統計而言,執行單元以及 retire 指令數量的成長替 Zen 5 IPC 貢獻最多效能提升幅度,資料路徑強化 ∕ 解碼和微指令快取次之,原本在 Zen 4 IPC 提升幅度最大的前端部分反而沒有提及。
▼ Zen 5 微架構讓效能提升的因素,最主要集中於執行單元數量和寬度提升。
讓我們同樣從處理器核心的前端出發:分支預測更為精準、輸出量提升、延遲更低已是每一代微架構的必修學分,L1 指令快取也同樣改善了頻寬和延遲(每時脈週期 32Byte 升級至 32Byte x 2)。比較重大的變化發生在解碼單元,直接從 Zen 4 的單一解碼單元每時脈週期輸出 4 個指令,直接翻倍來到 Zen 5 的 2 個解碼單元每時脈週期共輸出 8 個指令,微指令快取從每時脈週期輸出 9 個變成 6 x 2 個,微指令佇列配發數量也從每時脈週期 6 個提升至 8 個。
▼ Zen 5 微架構前端較大的變化位於解碼單元,從前一世代的 4 個指令翻倍為 8 個。

整數單元部分,ALU 從 4 個提升至 6 個、乘法單元變成 3 個、AGU 和分支單元分別多 1 個,並且更平均地安排每個執行單元。隨著執行單元數量的提升,dispatch ∕ retire 指令數量最高也來到 8 個。從簡報的圖示看來,Zen 5 排程器的規劃方式也有所不同,Zen 4 採用 2 個執行單元埠共用 1 個排程器的設計,Zen 5 則是改為含 ALU 功能的埠共用 1 個排程器、AGU 則共用另外 1 個,但 AMD 並未說明排程指令數量的變化。
▼ Zen 5 微架構整數部分新增多個執行單元,dispatch ∕ retire 同步提升至 8 個指令。

浮點數單元數量在 Zen 5 微架構並未升級,同樣有著 6 個(含 2 個浮點加法器、延遲從 3 個週期縮減至 2 個週期),主要因應 AVX-512 指令集進行調整。Zen 4 雖然也支援 AVX-512,卻是透過「double-pumped」的方式,讓寬度僅有 256bit 的浮點單元去執行 512bit 浮點 ∕ 向量運算,如今 Zen 5 已將浮點單元擴充至完整 512bit,代表執行 AVX-512 指令時相較前一世代更快。在 AMD 內部的 IPC 效能測試之中,成長幅度最高的部分也來自於執行 AVX-512 指令。
▼ Zen 5 微架構已將浮點數執行單元部分擴展至完整 512bit,執行 AVX-512 指令相較 Zen 4 微架構更為快速。排程器也升級至 3 個,每個包含 32 個條目,暫存器也因應 AVX-512 而加寬至 512bit ∕ 384 個條目。

因應執行單元數量擴增、浮點數單元寬度提升,餵資料的速度也必須加快。Zen 5 L1 資料快取從前一世代 32KB ∕ 8-way,升級至 48KB ∕ 12-way,單一時脈週期最高也從載入 3 筆 ∕ 儲存 2 筆升級為載入 4 筆 ∕ 儲存 2 筆資料(AMD 未說明 512bit 資料長度時的變化)。其餘 L2、L3 沒有變化,依舊是 1MB ∕ 16-way、32MB ∕ 16-way(victim 設計,L3 快取實際容量會跟隨核心數量、產品定位而變動)。
題外話,由於 AMD Ryzen 9000 系列桌上型處理器依舊採用與 Ryzen 7000 系列桌上型處理器相同的 cIOD,因此每個 CCD 向 cIOD 的讀寫頻寬應該也相同;每個 Infinity Fabric 時脈週期,CCD 向 cIOD 傳輸 16Byte 資料、cIOD 向 CCD 傳輸 32Byte 資料。(根據 AMD 簡報尾部的附註小字,Ryzen 9000 搭配 DDR5 記憶體的較佳運作速度應該仍是 DDR5-6000)
▼ Zen 5 L1 資料快取升級至 48KB ∕ 12-way,也同步提升讀寫頻寬。

AVX-512 完整效能加持
最後就是 IPC 比比看的時間,根據 AMD 的測試,Zen 5 相較 Zen 4 的 IPC 幾何平均提升幅度來到 16%,特別是那些使用到 AVX-512 指令的應用程式幅度最高,機器學習效能可提升 32%、Geekbench 5.4 的 AES-XTS 更高達 34%!
▼ 相較於 Zen 4,Zen 5 IPC 幾何平均提升幅度達 16%。
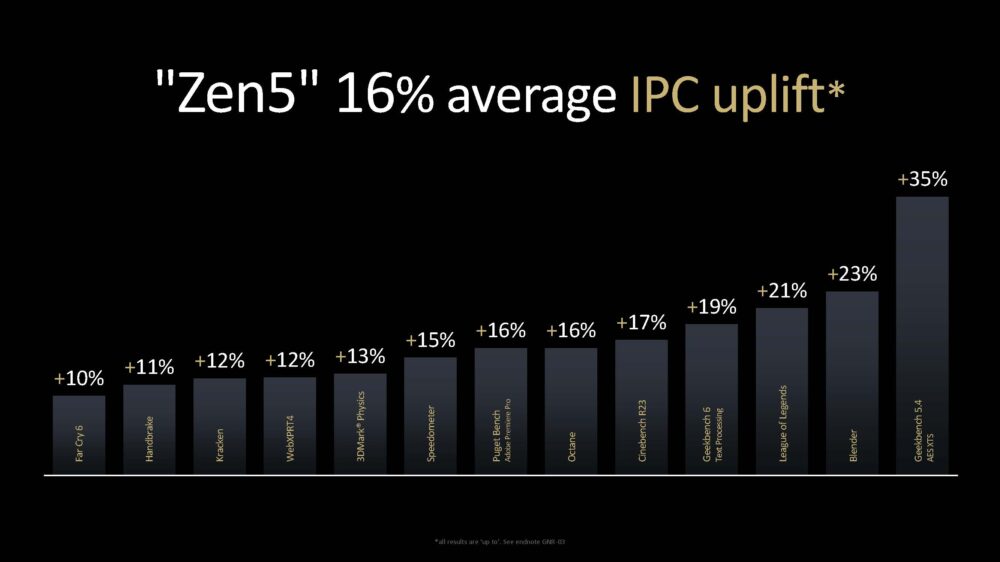
▼ 應用到 AVX-512 的指令,Zen 5 IPC 提升幅度更高!



