
今天是 AMD Ryzen 5000 系列桌上型處理器發售解禁的日子,我們將會陸續推出相關比較測試。另一方面,AMD Ryzen 5000 系列桌上型處理器從主要競爭對手贏得「最佳遊戲處理器」頭銜,這不僅僅是 Zen 微架構發展以來的多核心 / 多執行緒策略奏效,也是首次單核心 / 單執行緒效能勝過主要競爭對手。正所謂「外行看熱鬧,內行看門道」,效能數字比一比很簡單,Zen 3 微架構改進才是這一切的基礎。
單一 CCX 實體 8 核心
首先從比較明顯的改變切入,Zen/Zen+/Zen 2 微架構單一 CCX(Core Complex)為實體 4 核心,實體 4 核心共享 1 組 L3 快取。Zen 3 微架構每單位 CCX 則是改成實體 8 核心共享 1 組 L3 快取,並將核心與快取銜接方式改為環形架構,L3 快取容量直接使用前一代產品相加變成 32MB,但仍為 16-way。(註:Intel Tiger Lake Willow Cove L3 快取為 12MB / 12-way)
▼ Zen 3 單一 CCX 變更為實體 8 核心設計,順手也將前一世代 2 個 L3 16MB 快取整合成單一 L3 32MB 快取,並維持 16-way。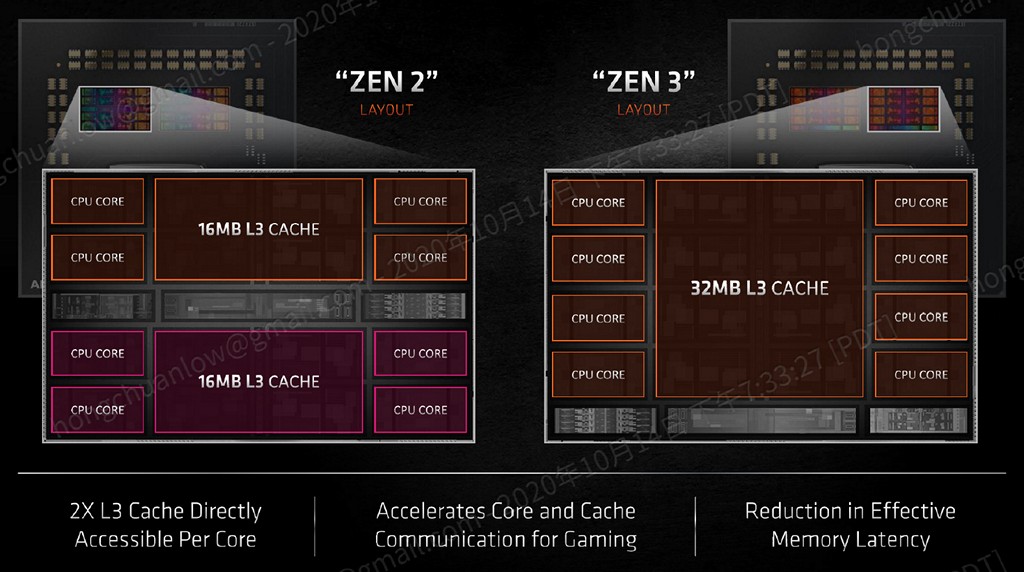
這麼做有什麼好處?AMD CTO Mark Papermaster 提到遊戲引擎通常有多個執行緒進行不同工作,例如對戰 AI、畫面渲染、音效、物理互動…… 等,其中資源管理執行緒負責載入遊戲資料,記憶體操作較為吃重,此時這個執行緒便可使用較大的 L3 快取強化效能,而前一世代存取超過 16MB L3 快取時,需要另行透過 Infinity Fabric,延遲較高。
提升快取容量是個雙面刃,雖然能夠提升 cache hit 成功率,不必從更慢的系統記憶體載入資料,但是也會增加 L3 存取延遲(Zen 2:39 個時脈週期、Zen 3:46 個時脈週期)。只是 AMD 在這方面應該經過測試評估,增加 L3 快取容量所增加的延遲,相對透過 Infinity Fabric 存取其它 CCX 的 L3 快取延遲更有利。
▼ Zen、Zen 2、Zen 3 各種快取與核心比較,可以看到 Zen 3 因 L3 快取容量上升至 32MB,存取延遲增加 7 個時脈週期。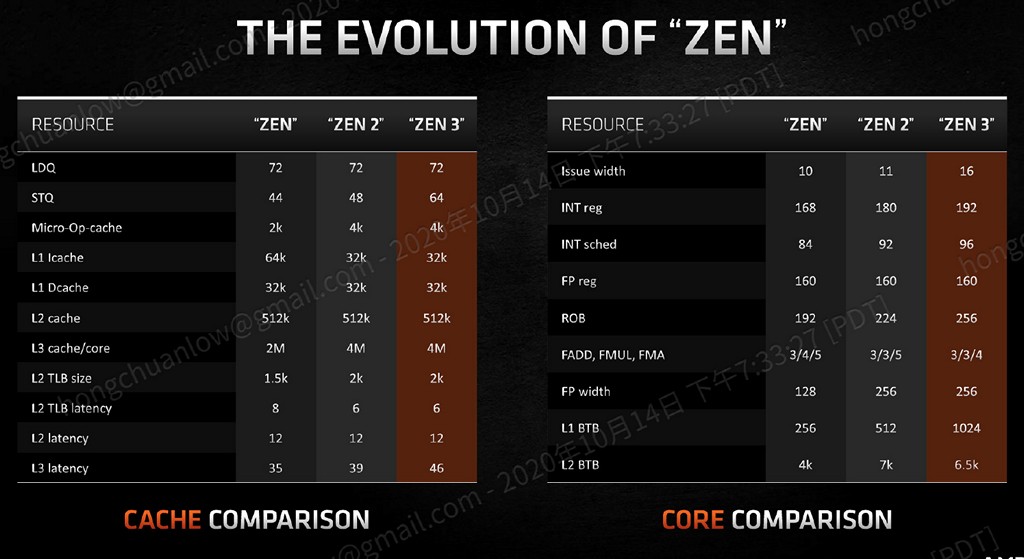
對了,Zen / Zen+ / Zen 2 / Zen 3 的 L3 快取都是 victim cache,從 L2 排除的資料才會進入 L3,Zen 3 微架構的 L2 標籤更會連帶複製至 L3,供 probe filtering(檢查要擷取的資料是否已在快取當中)與加速快取傳輸之用。(註:Intel Willow Cove 微架構 L3 快取從 Sunny Cove 的 inclusive 變更為 non-inclusive)
▼ Zen 3 快取架構。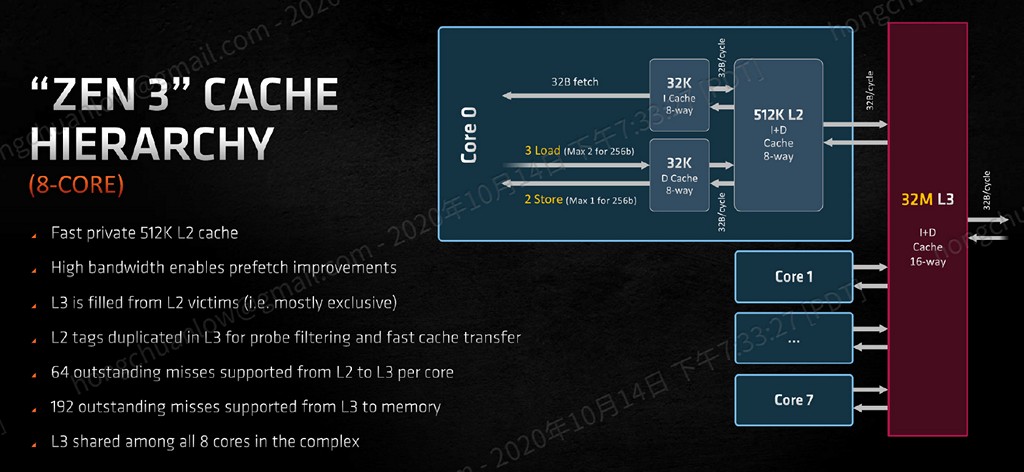
Ryzen 5000 系列桌上型處理器首發數款仍舊採用 chiplet 設計,採用 1 個 IOD(I/O Die)以及 1 個或 2 個 CCD(Core Chiplet Die,Zen 3 微架構單一 CCD 包含 1 個實體 8 核心 CCX)的封裝設計,IOD 向 CCD 每時脈週期能夠藉由 Infinity Fabric 傳輸 32Byte,而 CCD 向 IOD 只能傳輸 16Byte,因此若是使用記憶體頻寬測試軟體,啟用單一 CCD 型號相較雙 CCD 型號仍舊有著寫入速度減半的情形。
▼ Ryzen 5000 系列桌上型處理器內部單一 CCD 向 IOD 傳輸資料時,單一 Infinity Fabric 時脈週期依然只有 16Byte,因此處理器封裝僅包含 1 個 CCD 的型號,仍可見到記憶體寫入頻寬相較 2 個 CCD 型號減半的狀況。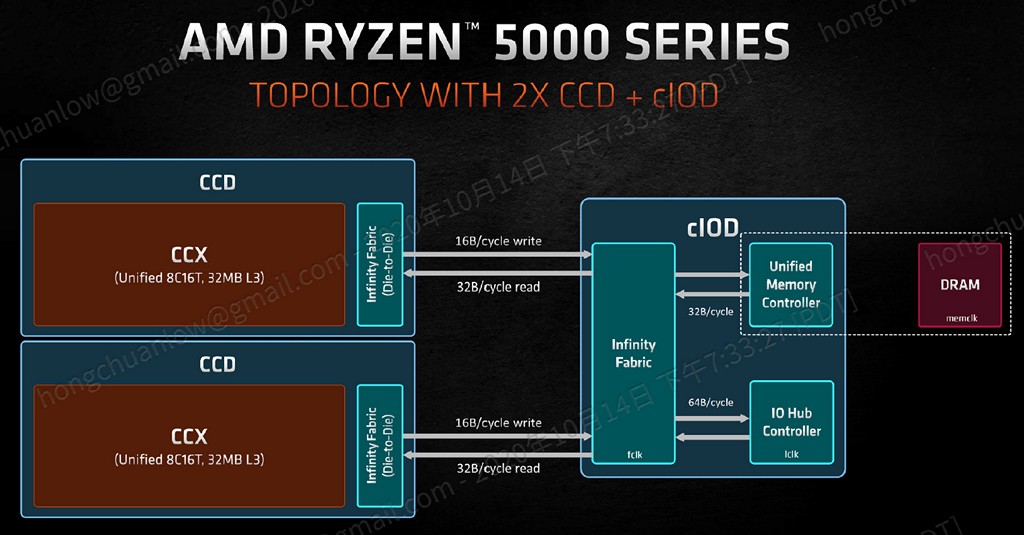
代號 Vermeer 處理器的 Ryzen 5000 系列桌上型處理器 IOD,與代號 Matisse 處理器 Ryzen 3000 系列桌上型處理器 IOD 相同,因此過往記憶體調整、超頻的經驗能夠沿用,mCLK、uCLK、fCLK資料傳輸最低延遲亦同樣出現於 1:1:1 情況。這一世代或許是受到 CCD 內部 Infinity Fabric 設計略有變化的影響,於 Matisse 的 1:1:1 極限大約是 1900MHz / DDR4-3800,而 Vermeer 極限則提升數個倍頻至 2000MHz/DDR4-4000。
▼ 記憶體時脈 mCLK、記憶體控制器時脈 uCLK、Infinity Fabric 時脈 fCLK 同步運作,於 Ryzen 5000 系列桌上型處理器有機會挑戰 2000MHz / DDR4-4000。
▼ Intel 於 Willow Cove 微架構宣布加入的 CET(Control-flow Enforcement Technology),Zen 3 同樣具備,用以抵禦 ROP(Return-Oriented Programming)攻擊。
7nm 嶄新設計 Zen 3
美國當地時間 10 月 8 日,AMD 正式宣布推出 Ryzen 5000 系列桌上型處理器,於提升 IPC 19% 的背後,提到 Zen 3 微架構能夠提供更寬的整數、浮點數執行路徑,更佳的記憶體存取效能,甚至是「zero bubble」不會產生閒置空泡的分支預測準確度(絕大多數情況啦)。
Zen 3 之於 Zen 2 的變化,更甚 Zen 2 之於 Zen/Zen+,Zen 3 並非是 Zen 2 的強化變體,而是重新設計的微架構,也因此能夠延續 TSMC 7nm 製程,又保持將 2 個 CCD 放入 AM4 封裝尺寸的前提之下,以略為成長的晶粒尺寸與電晶體數量(Matisse / Zen 2 CCD:74mm2 / 38 億、Vermeer / Zen 3 CCD:80.7mm2 / 41.5 億),達成 IPC 成長 19%。
▼ Zen 3 微架構改進總覽。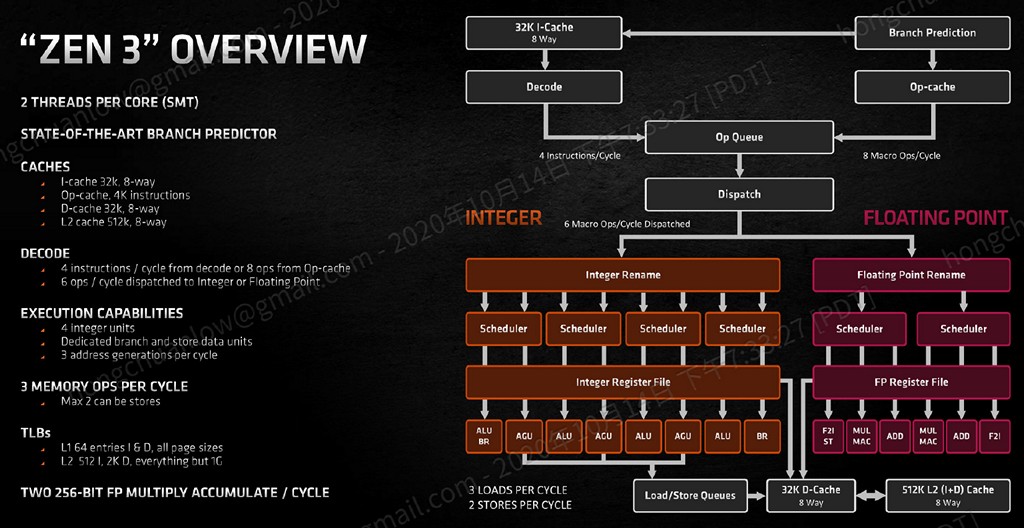
▼ Zen 2 與 Zen 3 的比較。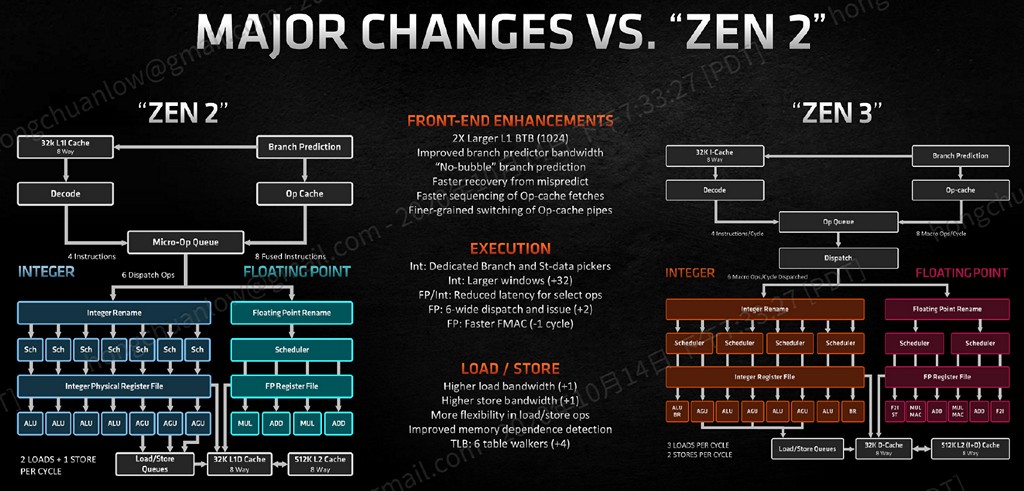
Zen 3 前端擷取、解碼、分支預測帳面規格變更不大,但為提升 IPC 貢獻不少,強化擷取速度、提升分支預測成功機率與頻寬、降低分支預測失敗後的回復延遲、微指令快取傳輸速度更快,與指令快取之間的切換速度亦隨之增加。
Zen 3 分支預測器仍具 TAGE 形式,L1 BTB(Branch Target Buffer)從 Zen/Zen+ 的 256 個條目、Zen 2 的 512 個條目,再次翻倍至 1024 個,L2 BTB 則是從 4096 個、7168 個,Zen 3 略降至 6 千 5 百餘個,ITA(Indirect Target Array)則是上升 50% 至 1 千 5 百餘個。
▼ Zen 3 前端擷取、解碼採用微調提升分支預測命中率為主,並適度提升部分區塊的容量。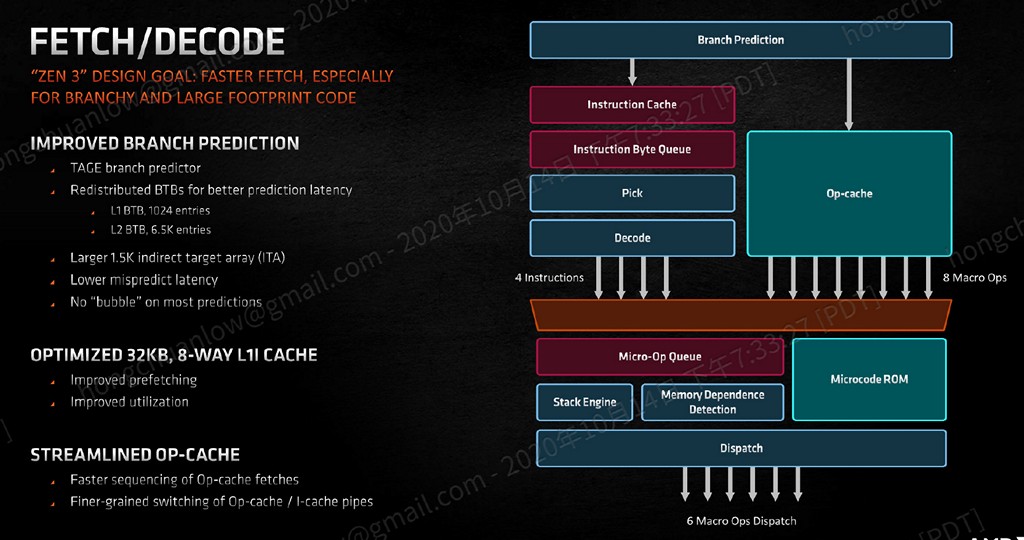
從前端到執行單元,Zen 3 與 Zen 2 於同一時脈週期最高能夠派發 6 條融合巨集指令至整數單元與浮點數單元。是的,AMD Zen 3 執行單元埠仍舊維持整數、浮點數分離設計,而 Intel 則是從 P6 微架構開始就採用混合結構,小核心如 Tremont 則是維持整數、浮點數分離。
▼ Zen 3 維持整數、浮點數執行單元埠分離設計,單一時脈週期最高維持派發 6 條融合巨集指令。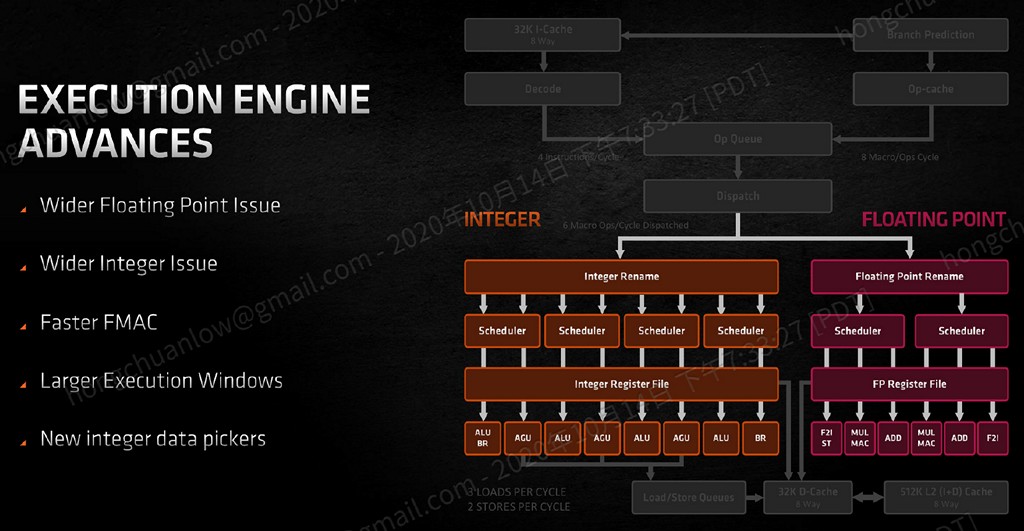
我們先來看看相較於整數,Zen 3 微架構變化較小的浮點數部分,原本 Zen 2 浮點運算 ADD 加法、MUL 乘法/MAC 乘積累加單元各有 2 個,Zen 3 則是將 F2I(Float to Integer)與儲存單元獨立出來,各新增 1 個 F2I/儲存和 1 個儲存單元。也因為這 2 個新的單元,Zen 3 浮點單一時脈週期能夠 issue 的數量也從 Zen 2 的 4 個提升至 6 個,前方排程器則是從 4 個單元共用 1 組,變成 3 個單元共用 1 組(共 2 組)。
另一方面,Zen 3 也將縮減浮點數運算延遲列為改善目標,其中包含增加排程器條目數量、強化配發頻寬,MAC 乘積累加運算所需時間則是縮減到 4 個時脈週期(MUL 乘法運算應維持 Zen 2 的 3 個週期)。雖然 AMD 並不急著導入 AVX-512,但仍替 Zen 3 加入於 Intel Sunny Cove 微架構新增的 VAES 和 VPCLMULQDQ 指令,用以加速加密運算。
▼ Zen 3 浮點數元區塊提升配發、issue 頻寬,降低 MAC 運算延遲至 4 個時脈週期,並將 F2I、儲存單元獨立出來。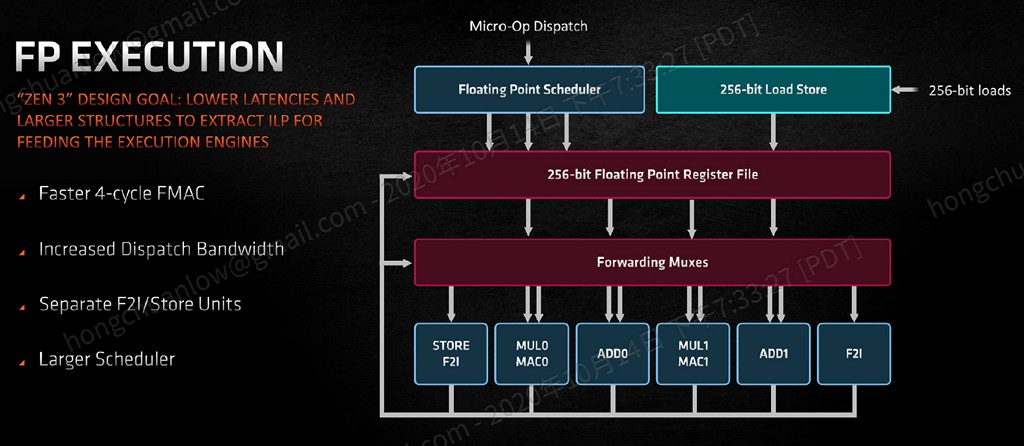
▼ AMD 替 Zen 3 添加 VAES 和 VPCLMULQDQ 指令。
接著是變化比較大的整數執行單元區塊,ALU、AGU 各自依舊維持 4 個、3 個不變,但是原本每個 ALU 享有 1 個獨立的 16 條目排程器、3 個 AGU 共享 1 個 28 條目排程器,改為兩兩搭配享有 1 個 24 條目的排程器,其中多出來的 ALU 另行與新增的獨立分支單元組成 1 組,因此排程器共計有 96 條目,相較 Zen 2 多出 4 個,整數暫存器也微幅上調至 192 個。
▼ 因應更多的執行單元,Zen 3 整數部分從 7 issue 提升至 10 issue,排程器、暫存器數目亦略為上升。
路徑更寬、數量更多
Zen 3 於 AGU 之後的載入/儲存佇列以及 L1 32KB 資料快取,面對 256bit 資料長度,仍舊可以於單一時脈週期提供 2 個讀取、1 個儲存能力,但如果遇到比較短的資料,則最多可以達成 3 個讀取、2 個儲存能力。也因為如此,Zen 3 整數區塊單一時脈週期最高能夠 issue 10 條指令(4 條 ALU、3 條 AGU、1 條分支、2 條儲存,Zen 2 則為 4 條 ALU、3 條 AGU 共 7 條)。
▼ Zen 3 L1 32KB 資料快取單一時脈週期支援 3 個讀取、2 個載入,若是遇到 256bit 資料長度,則維持 Zen 2 的 2 個讀取、1 個儲存。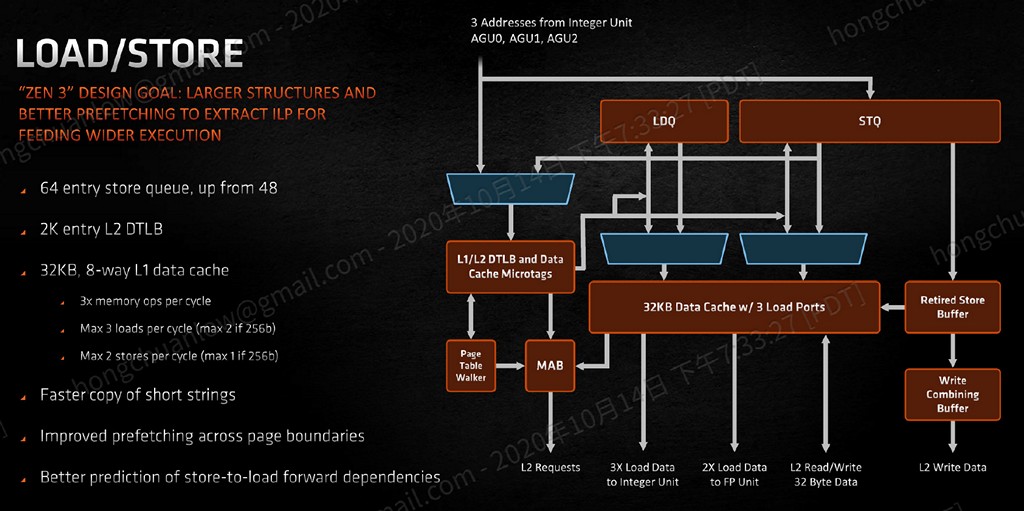
相對應的儲存佇列條目,從 Zen 2 的 48 個上升至 64 個,ROB(Re-Order Buffer,將執行單元亂序執行的結果,重新排回原本的順序)也從 224 個上升至 256 個。相對而言,L2 快取則沒有變化,與 L1、L3 的傳輸頻寬不變、512KB 容量不變、8-way 不變。而負責查找記憶體分頁表,將虛擬位址對應實體位址的 page table walker,亦從 Zen 2 的 2 個提升至 6 個。
▼ Zen 3 提升載入/儲存的記憶體依賴性偵測機制,並額外加入 4 個 page table walker(總共 6 個)。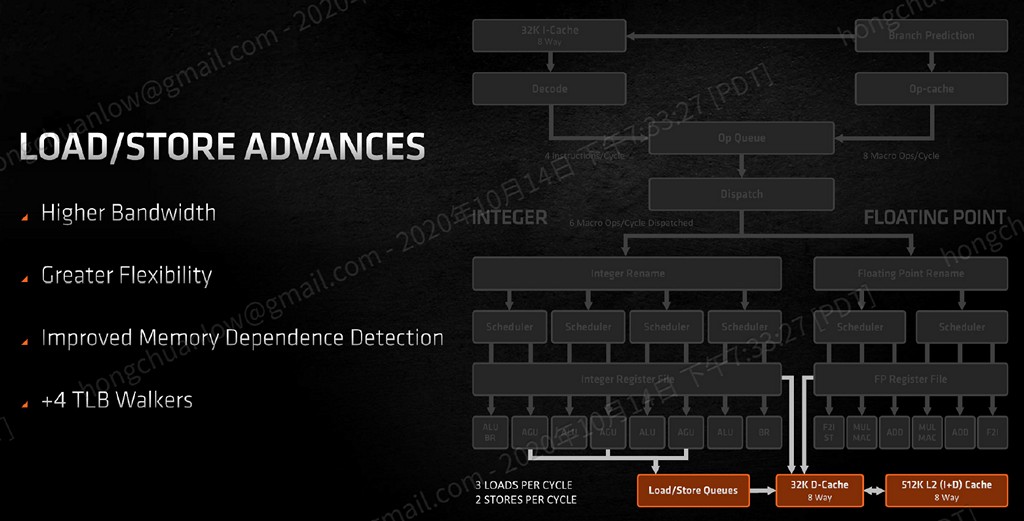
最近大家很喜歡在廠商的簡報上畫圖量測,追根究柢效能提升幅度,但我們不去細究數字。依據 AMD 簡報來看,Zen 3 相對於 Zen 2 的 19% IPC 提升幅度,大約四分之一由改善載入/儲存方式所貢獻,大約四分之一由前端改進所貢獻,其餘快取預取、執行單元、分支預測器、微指令快取加起來大約貢獻二分之一。
▼ Zen 3 19% IPC 成長幅度,載入/儲存、前端改進各佔四分之一,快取預取、執行單元、分支預測器、微指令快取加起來大約貢獻二分之一。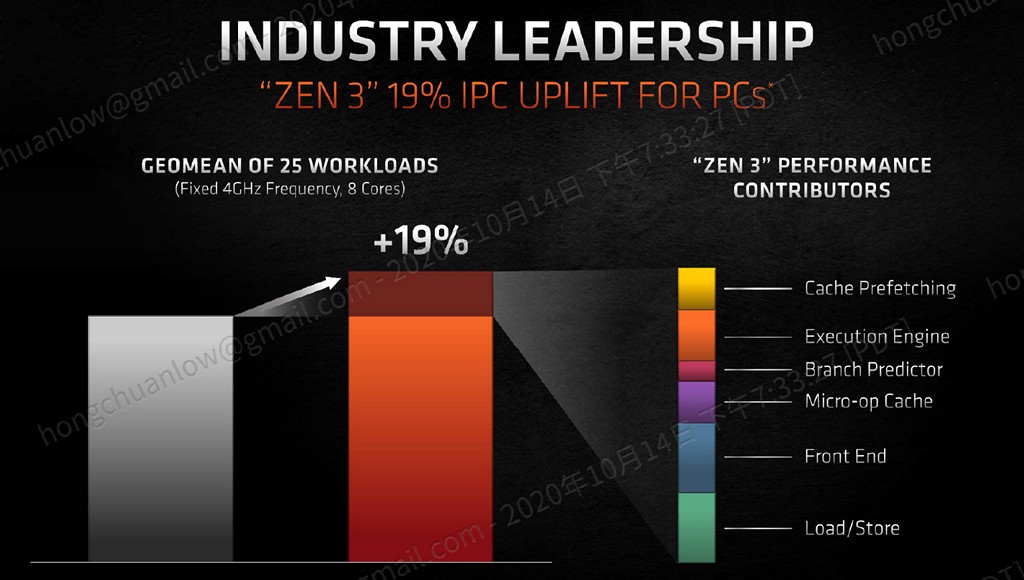
▼ Zen 3 相對於 Zen2 於各種不同的負載測試提升幅度一覽,特別是那些強調單核效能的線上競技型遊戲進步最多。


